
Semantyczne SEO to nauka opisywania rodzajów Entities (podmiotów) na świecie oraz sposobów ich powiązania. Jedną z metod jest określenie słownictwa dotyczącego rzeczy i powiązań kontekstowych pomiędzy nimi. Słownictwo, które umożliwia stosowanie semantycznego SEO nosi nazwę Schema.org.
Schema.org nie jest jedynie słownictwem sieci semantycznej (Semantic Web), ale jest również utrzymywane i wspierane przez Google, Bing, Yahoo oraz Yandex. Trzeba jednak pamiętać, że ustrukturyzowane dane nie są jedyną metodą optymalizacji sieci semantycznej tylko stanowią jedną ze skutecznych metod w przypadku posiadania dobrej treści.
W przypadku stron z dużą ilością treści, ustrukturyzowane dane mogą pomóc w opisywaniu, nadawaniu kategorii i łączeniu treści ze sobą w sposób pomagający wyszukiwarkom w lepszym zrozumieniu strony. Wiele osób wie jak tworzyć i wdrażać ustrukturyzowane dane, ale nie wszyscy wiedzą jak je optymalizować pod kątem sieci semantycznej.
Czym są dane?
Dane to nic innego jak zbiór informacji. Jednym z celów nauki o danych jest ustrukturyzowanie danych sprawiając, że są łatwe w interpretacji i wykorzystaniu. Dane dzielą się na dwie grupy:
- Ustrukturyzowane dane
- Nieustrukturyzowane dane


Czym są nieustrukturyzowane dane?
Nieustrukturyzowane dane (lub nieustrukturyzowane informacje) są informacjami, które nie posiadają wstępnie określonego modelu danych lub nie są zorganizowane we wstępnie ustalony sposób. Nieustrukturyzowane informacje zwykle zawierają wiele treści i mogą zawierać dane, liczby oraz istotne fakty.
Czym są ustrukturyzowane dane?
Ustrukturyzowane dane to standardowa forma dostarczania informacji na temat strony oraz klasyfikowania jej treści. Przykładowo na stronie z przepisami dostępne są informacje o składnikach, czasie gotowania, temperaturze, kaloriach, itp.
Jaki jest cel stosowania ustrukturyzowanych danych?
Zadaniem ustrukturyzowanych danych jest sprawienie, że język ludzki będzie czytelny dla maszyn. Ustrukturyzowane dane są danymi posiadającymi opisy oraz są one sformatowane w standardowy i łatwo dostępny sposób. Opisy danych są czymś, co określamy pojęciem metadane. W związku z tym ustrukturyzowane dane zapewniają maszynom i wyszukiwarkom możliwość zrozumienia i przeanalizowania danych.
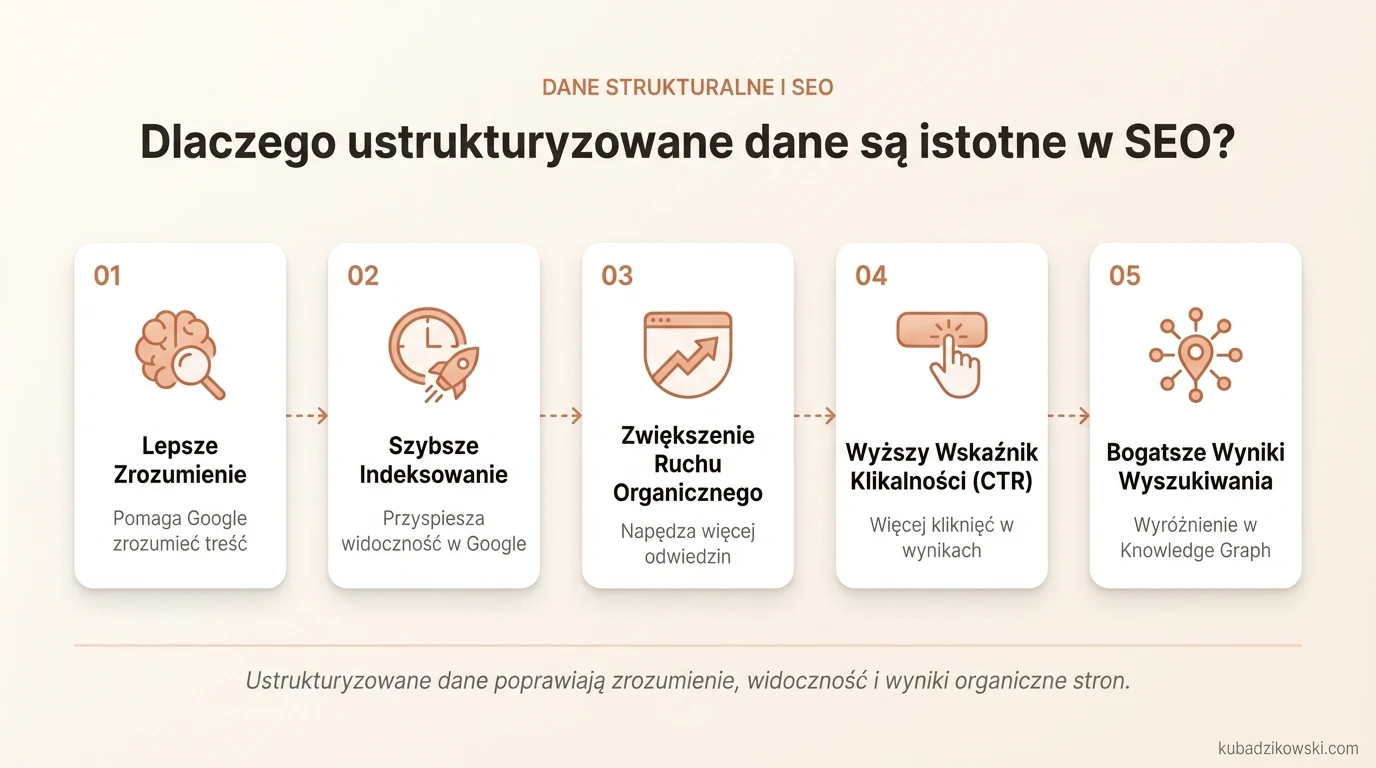
Dlaczego ustrukturyzowane dane są istotne w SEO?
Ustrukturyzowane dane są ważne w SEO, ponieważ ułatwiają Google zrozumienie tego co prezentują strony internetowe lub różne usługi.
Korzyści związane z używaniem ustrukturyzowanych danych obejmują między innymi zwiększenie organicznego ruchu, wzrost wskaźników klikalności, lepszą widoczność w rezultatach wyszukiwania, szybsze indeksowanie, dostarczanie informacji do Google Knowledge Graph oraz ogłaszanie wydarzeń specjalnych.

Zwiększenie organicznego ruchu na stronie
Ustrukturyzowane dane mogą zwiększyć ruch organiczny na stronie. Dzięki wprowadzaniu takich danych, algorytmy wyszukiwarki mogą lepiej zrozumieć treść stron internetowych, a to z kolei wpływa korzystnie na optymalizację SEO.
Zwiększenie wskaźnika klikalności (CTR)
Ustrukturyzowane dane mogą wpłynąć korzystnie na rezultaty organiczne. Jedną z korzyści jest zwiększenie wskaźnika klikalności strony internetowej. Bogate rezultaty mogą obejmować obrazy, opisy, FAQ lub inne elementy, które nie są tekstami.
Szybsze indeksowanie
Ustrukturyzowane dane mogą pomóc Google w łatwiejszym skanowaniu i szybszym indeksowaniu strony internetowej. Skanowanie jest kosztowne oraz istnieje sporo powielonych i niskiej jakości treści, które wyszukiwarka chce trzymać z dala od swojego indeksu. Warto więc zadbać o swój Crawling Budget.
Dopasowanie do intencji użytkownika
Maszyny, takie jak wyszukiwarki semantyczne, wykorzystują ustrukturyzowane dane po to, aby odczytać i zrozumieć podstawowe Entities (podmioty) danej strony przy powiązaniu z systemami rozumowania. To pozwala użytkownikom na znalezienie tego co poszukują, dzięki zrozumieniu intencji ich wyszukiwania.
Dostarczanie informacji do Knowledge Graph
Ustrukturyzowane dane dostarczają do Google Knowledge Graph odpowiednie informacje na temat twórcy strony, jego działalności oraz samej strony. Dodatkowo dane te mogą być wykorzystywane do zasilania Google Knowledge Graph. Jest to baza danych, która łączy w sobie wszystkie typy danych, jakie Google znajduje w sieci. Dane te są wyświetlane w panelu wiedzy Google.
Dostarczanie informacji do Google Knowledge Graph znacznie ułatwia działanie Google. W ten sposób przekazywane są istotne dane na temat rezultatów wyszukiwania strony najlepiej jak to tylko możliwe.
Ogłaszanie wydarzeń specjalnych
Ustrukturyzowane dane mogą pomóc Google w wyświetlaniu specjalnych wydarzeń, takich jak wyniki meczów, aktualne możliwości zatrudnienia, itp.
Wydarzenia w Google ułatwiają ludziom odkrywanie oraz uczestnictwo w wydarzeniach za pośrednictwem rezultatów wyszukiwania Google oraz innych produktów, takich jak Google Maps. Ta funkcja zapewnia wiele korzyści, takich jak więcej interaktywnych rezultatów oraz zwiększenie szans na odkrycie i konwersję.
Czym jest semantyczne SEO?
Semantyczne SEO to praktyka optymalizacji treści strony internetowej w sposób umożliwiający wyszukiwarkom zrozumienie znaczenia i kontekstu treści.
Obejmuje to proces budowy modelu semantycznego strony internetowej, jak również tworzenie mapy tematycznej i wewnętrznego linkowania.
Obejmuje to również stosowanie powiązanych słów i fraz, wykorzystywanie tytułów i nagłówków oraz korzystanie z prawidłowo ustrukturyzowanych danych, aby treść była łatwiejsza do odczytania i zrozumienia przez roboty wyszukiwarek.
Ustrukturyzowane dane są ważne w semantycznym SEO, ponieważ po ustaleniu ontologii opisującej Entities i ich powiązania, pomagają wyszukiwarkom w zrozumieniu treści znajdującej się na stronie internetowej oraz kontekstu w jakim została wykorzystana.
Poprzez korzystanie z technik semantycznego SEO można zwiększyć znaczenie oraz dokładność treści na stronie internetowej. To sprawia, że będzie ona bardziej atrakcyjna dla wyszukiwarek, jak również użytkowników. Pozwala to na poprawę widoczności strony w rankingach na stronach z rezultatami wyszukiwania, a także zwiększa ruch na stronie.
Czym są Semantic Triples? Jak działa Schema Markup?
Semantic Triple (semantyczna trójca) to zestaw trzech Entities kodujący zdanie na temat danych semantycznych w formie: podmiot-orzeczenie-przedmiot (ID, właściwość, wartość).
Robot Google analizuje dane i przetwarza je na tria, które można umieścić w bazie danych grafu. Takie trójce są uniwersalnym oraz fundamentalnym atomem informacji. W związku z tym zrozumienie Semantic Triple jest kluczowe pod względem optymalizacji ustrukturyzowanych danych oraz treści w sieci semantycznej.
Jak metadane mogą opisywać dane z wykorzystaniem trójcy? Przykład: (np. „Bob →ma → 35 lat” lub „Bob → zna → Johna). Taki format pozwala na zaprezentowanie wiedzy w sposób możliwy do odczytania przez maszynę. Każda część trójcy schema.org posiada unikalny identyfikator. Można wykorzystać URI, aby zaprezentować te ID – na przykład zdanie „Bob zna Johna” może zostać zaprezentowane w schema.org jako:
{
“@context”: “https://schema.org”,
“@type”: “Person”,
“@id”: “Person1”,
“name”: “Bob”,
“knows”: {
“@context”: “https://schema.org”,
“@type”: “Person”,
“@id”: “Person2”,
“name”: “John”
}}
W schema.org każdy fragment informacji jest przechowywany oraz dostępny w formacie trójcy.
Zawsze możliwe jest rozbicie elementy na precyzyjne zestawy trójcy. Pojedyncze dopasowanie wzoru trójcy, takie jak przedstawione powyżej, jest bez wątpienia przydatne, ale w ramach jednego wzoru trójcy możliwe jest przedstawienie ograniczonej ilości rzeczy. W związku z tym trójce mogą tworzyć bardziej złożone model z wykorzystaniem trójcy jako podmiotu lub orzeczenia w innych trójcach, na przykład Susan → powiedziała, że: (Bob → zna → Johna).
Jak wykorzystywać trójce, aby tworzyć treści, które łatwo przetwarza się na ustrukturyzowane dane?
Zamiast wykorzystywania ustrukturyzowanych danych do opisywania treści, można napisać ją w sposób, który umożliwia jej łatwe przetworzenie na ustrukturyzowane dane z wykorzystaniem trójcy.
Wyszukiwarki semantyczne, takie jak Google, korzystają z baz wiedzy, takich jak Wikipedia, musicbrainz czy też Yahoo Finance, jako źródeł informacji potrzebnych do opisywania danych.
Są one często wypełnione częściowo lub całkowicie ustrukturyzowanymi danymi, które są łatwe w użytku. Google zaczęło również wykorzystywać dane z nieustrukturyzowanych źródeł, takich jak strony różnych organów, instytucji i firm.
Tworząc taką treść, należy pisać w sposób łatwy do przetworzenia na dane ustrukturyzowane.
- Pisanie w trójcach lub formatach podmiot-> czasownik-> przedmiot.
- Korzystanie ze stron tytułowych z tematem strony w formie tytułu i nagłówka.
Jeśli chodzi o dane, wyszukiwarka chce widzieć trójcę.
Nieustrukturyzowane dane wydają się być mniej elastyczne, ale są bardziej unikalne niż ustrukturyzowane dane. Zapewnia to większą różnorodność w sieci semantycznej.
Aby zoptymalizować trójcę semantyczną, należy w pierwszej kolejności zrozumieć jej elementy (ID, właściwość i wartość). Każde ID to Entity, a każdy Entity (podmiot) posiada swoje właściwości. Wartością Entity może być ID innego Entity, które również posiada inne właściwości. Elementy te są ze sobą wewnętrznie powiązane i wyraźne, a ich wartość zależy od kontekstu.
Jak zoptymalizować Schema Markups w SEO?
1. Przestrzeganie ogólnych wytycznych
- Prostota: Zasadą prostego, ale silnego SEO jest to, że Schema Markups (znaczniki schematu) powinny reprezentować główny Entity (podmiot) strony. Dzięki temu ustrukturyzowane dane znajdujące się na stronie odpowiadają jej głównemu elementowi.
- Zapewnienie stosowności: W SEO bardzo istotny jest kontekst. Należy więc znaleźć inne odpowiednie Entities i opisać ich powiązania z Entity podstawowym.
- Nie należy oznaczać nieodpowiedniej treści: Należy zachować skupienie. Nie trzeba więc oznaczać niepotrzebnych treści, takich jak pasek nawigacyjny, menu główne, stopka, itp., jeśli takie Entities nie są właściwe dla Entity podstawowego.
2. Optymalizacja typu schematu
- Bycie konkretnym: Wybór właściwego typu schematu to fundament optymalizacji wartości Entities w oczach wyszukiwarki.
Na przykład, przy opisywaniu kliniki dentystycznej można wybrać schemat biznesu lokalnego albo placówki medycznej. Obie te odpowiedzi są częściowo, ale nie całkowicie poprawne. Wybierając tylko jedną z nich można utracić pewne właściwości wymagane przez drugi typ.
Można używać obu typów jednocześnie, jednak najlepszym wyjściem jest wybór schematu dentysty. Taki schemat łączy właściwości lokalnego biznesu oraz placówki medycznej i jest najlepszym opisem kliniki dentystycznej.
W znaczniku należy wykorzystać jak najbardziej konkretne pasujące nazwy typów i właściwości określone w schema.org.
- Dokładność: Im większa dokładność, tym lepiej dla SEO. Schemat to po prostu opis tego co znajduje się na stronie internetowej. W związku z tym nie zaleca się dodawanie do schematu informacji, które nie istnieją na stronie. Jeśli pojawi się niezgodność pomiędzy schematem, a informacjami na stronie, wówczas zgodnie z informacjami Google, strona uzyska gorszą pozycję w rankingach lub zostanie oznaczona jako bezwartościowa.
- Im więcej, tym lepiej: opisując Entity (podmiot) na stronie internetowej, większa ilość dostarczanych informacji ma korzystny wpływ na SEO. Należy tylko upewnić się, że wszystkie takie dane istnieją na stronie.
- Wiele elementów: Opisywanie i powiązywanie wielu elementów jest zaawansowaną praktyką SEO. Wiele elementów na stronie internetowej oznacza, że istnieje więcej niż jedna rzecz na stronie. Przykładowo strona może zawierać przepis, film pokazujący jak przygotować potrawę na bazie przepisu, informacje Breadcrumb jak ludzie mogą odkryć dany przepis, itp. Te wszystkie informacje widoczne dla użytkownika mogą zostać oznaczone danymi strukturalnymi ułatwiając wyszukiwarkom takim jak Google zrozumienie informacji znajdujących się na stronie. W przypadku dodania większej liczby elementów znajdujących zastosowanie dla strony Google ma większy obraz tego o czym jest dana strona i może ją wyświetlać przy wyszukiwaniu różnych elementów.
3. Optymalizacja właściwości schematu
Właściwości stanowią opis Entity. Aby zoptymalizować właściwości schematu SEO, należy określić podstawowy Entity z wykorzystaniem „mainEntity” oraz opisać jego relację z innymi Entity korzystając z URL „sameAs” oraz „About”.
- Określenie podstawowego Entity (podmiotu): Przy określaniu podstawowego Entity, właściwość mainEntity umożliwia wyrażenie powiązania pomiędzy stroną, a podstawowym Entity. Na przykład należy wykorzystać mainEntity, aby wyjaśnić, który z wielu Entities jest głównym dla danej strony.
- Wykorzystanie URL: Właściwość URL powinna być zarezerwowana dla bardziej oficjalnych stron internetowych.
- Powiązanie danych: Właściwość sameAs wiąże się również z rzeczą na stronie, która określa ją w sposób pośredni. W przypadku strony Wikipedia lub strony produktu, jako sameAs można uznać oficjalną stronę producenta ze specyfikacjami.
- About a mainEntity: Funkcja About jest podobna do mainEntity z dwiema kluczowymi różnicami. Po pierwsze About może odnosić się do wielu Entities/tematów, podczas gdy mainEntity powinno się używać tylko z tematem głównym. Po drugie, pewne strony posiadają podstawowy Entity opisujący pewne inne Entity. Na przykład, jedna strona internetowa może wyświetlać artykuł z aktualnościami na temat określonej osoby. Inna strona może zawierać zdjęcie z opisem konkretnego produktu. W takich przypadkach mainEntity dla stron powinien odnosić się do artykułu w aktualnościach lub opisu (kolejno), podczas gdy About będzie poprawne dla osoby lub produktu.
- Wykorzystanie obrazów: Dobrą praktyką SEO jest upewnienie się, że obraz jest właściwy dla strony, na której się znajduje. Należy wykorzystać URL obrazu w celu jego identyfikacji. Wszystkie URL obrazów muszą być możliwe do skanowania i indeksowania.
4. Optymalizacja ID schematu
Funkcja identyfikatora lub ID schematu oznacza identyfikator jakiegokolwiek elementu, takiego jak kod ISBN, GTIN, UUID, URL, URI, sameAs, itp. Schema.org zawiera dedykowane funkcje potrzebne do reprezentowania wielu takich elementów jako teksty lub linki URL (URI).
ID jest wykorzystywane do określania Entities i łączenia ich. Funkcja sameAS oraz URL stanowią szczególne przypadki ID.
Można przydzielić dowolną nazwę swojemu ID, ale najlepiej jest przydzielić tag ID HTML opisywanego Entity.
Porada SEO: Jeśli istnieje wiele przydatnych elementów, które są ze sobą połączone (np. przepis i film z jego wykonania), należy użyć @id zarówno w elementach przepisu jak i filmu, aby ustalić, że film dotyczy przepisu znajdującego się na stronie. W przypadku braku połączenia tych elementów, wyszukiwarka Google może nie wiedzieć, że dany film może być pokazywany wraz z przepisem.
Jak zoptymalizować ustrukturyzowane dane pod kątem SEO
Jednym z dobrych sposobów przekazania Google informacji na temat powiązań ze światem rzeczywistym jest budowa sieci semantycznych. Mówiąc krótko, sieć semantyczna umieszcza dane w kontekście poprzez linkowanie i osadzanie metadanych semantycznych. Pozwoli to na odejście od pojedynczych odłączonych schematów oraz pozwala na budowanie sieci semantycznych grafów wiedzy, które lepiej reprezentują Entities oraz ich kontekst.
1. Zapewnienie kontekstu poprzez połączenie własnych Entities ze znanymi Entities
Zdolność danych strukturalnych do łączenia informacji z wielu źródeł jest pożądaną i bardzo potężną funkcją, która może być wykorzystywana w semantycznym SEO.
Nazywanie Entities jest zadaniem przypisania unikalnego identyfikatora do Entities (takich jak sławne osoby, lokalizacje lub firmy). Na przykład w angielskim zdaniu „Paris is the capital of France” trzeba ustalić, że „Paris” odnosi się do stolicy Francji, a nie do Paris Hilton.
2. Zagnieżdżanie właściwych Entities
Zagnieżdżanie to doskonała praktyka semantyczna, która jest oparta o definiowanie charakteru powiązań pomiędzy Entities (podmiotami).
Niektóre Entities są niemożliwe do zidentyfikowania samodzielnie, ale mogą zostać zagnieżdżone w większym Entity, jako jego część.
Dodatkowe elementy są pogrupowane w ramach elementu głównego. Jest to przydatne w grupowaniu elementów powiązanych (np. przepis wraz z filmem).
3. Stworzenie sieci semantycznej
Sieć semantyczna to baza wiedzy prezentująca powiązania semantyczne pomiędzy koncepcjami w sieci. Jest to często stosowane jako forma prezentowania wiedzy.
Sieć semantyczna może zostać utworzona na przykład jako graf bazy danych lub mapa koncepcji. Typowe standardowe sieci semantyczne są wyrażane jako trójce semantyczne.
Sieci semantyczne pomagają robotom rozpoznawać wszystkie Entities (podmioty) na stronie internetowej, w szczególności podstawowy Entity oraz zrozumieć wszystkie informacje na jego temat oraz na temat powiązań z innymi Entities.
4. Zestawienie strony z bogatymi rezultatami
Znaczniki schematu kwalifikacji bogatych rezultatów wymagają od webmasterów dostarczenia specyfikacji na temat ich Entities, takich jak zdjęcia, opisy, ceny, itp. Takie wymagania i specyfikacje bogatych rezultatów są korzystnym źródłem danych sieci semantycznej. Dlatego jest to poprawna technika semantycznego SEO.
Bogaty rezultat snippet (fragment) może sprawdzić znaczniki pod kątem ogólnych wytycznych znajdujących zastosowanie dla wszystkich fragmentów. Wytyczne te należy przestrzegać, aby możliwe było dołączenie ustrukturyzowanych danych w rezultatach Google.


