

Treści generowane przez sztuczną inteligencję stają się zarówno inspiracją, jak i wyzwaniem, otwierając drzwi do dezinformacji, naruszeń prywatności czy problemów etycznych. Jak algorytmy tworzą realistyczne, ale często fałszywe materiały? Jak deepfake’i zagrażają społecznym wartościom? Artykuł omawia zagrożenia AI, od destabilizacji społeczeństw po erozję zaufania do mediów i konieczność regulacji w celu ochrony jakości treści oraz wiarygodności informacji.
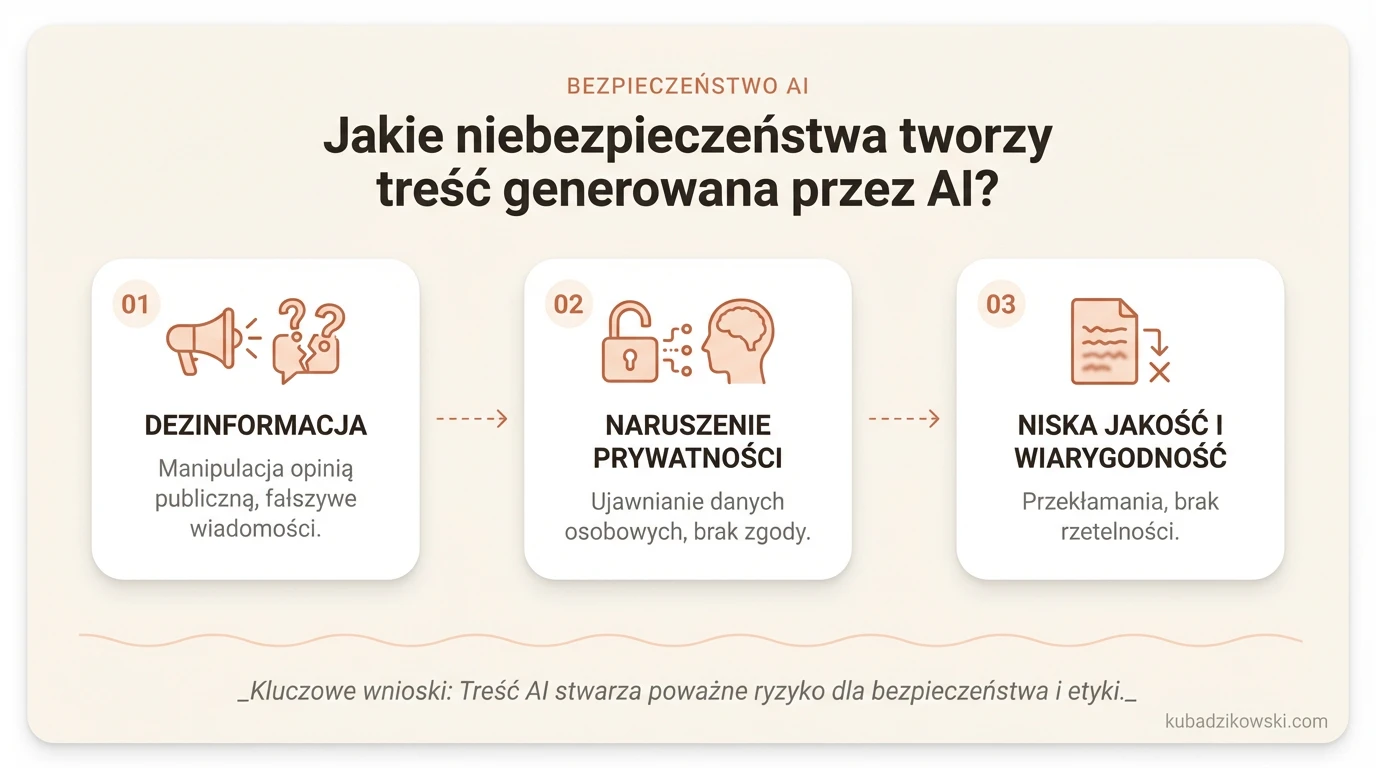
Jakie niebezpieczeństwa tworzy treść generowana przez AI?
Treści generowane przez sztuczną inteligencję stwarzają wiele wyzwań, które mogą wpływać na bezpieczeństwo, prywatność i wiarygodność informacji. Jednym z najpoważniejszych problemów jest dezinformacja. Algorytmy potrafią tworzyć teksty niemal nie do odróżnienia od tych pisanych przez ludzi, co otwiera furtkę do manipulowania opinią publiczną i rozprzestrzeniania fałszywych wiadomości.
Kolejnym istotnym zagrożeniem jest naruszenie prywatności. Systemy AI mogą przypadkowo ujawniać wrażliwe dane osobowe lub wykorzystywać je w sposób niezgodny z prawem. Przykładowo, modele językowe często przetwarzają poufne informacje bez wyraźnej zgody użytkowników, co prowadzi do poważnych konsekwencji prawnych i etycznych.
Jakość treści również pozostawia wiele do życzenia. Teksty generowane przez AI często zawierają błędy merytoryczne lub są tendencyjne. W sektorach takich jak medycyna czy finanse, nieprawidłowe dane mogą skutkować błędnymi decyzjami o daleko idących skutkach.
Nie można też pominąć kwestii etycznych i prawnych. Sztuczna inteligencja może generować treści nieetyczne, np. obraźliwe lub szkodliwe społecznie. Ponadto istnieje problem naruszania praw autorskich – algorytmy często korzystają z istniejących dzieł bez odpowiednich uprawnień.
Na poziomie globalnym treści tworzone przez AI zwiększają również ryzyko cyberataków, czyniąc systemy informatyczne bardziej podatnymi na zagrożenia. Wszystkie te czynniki podkreślają pilną potrzebę wprowadzenia skutecznych regulacji i mechanizmów kontroli nad wykorzystaniem sztucznej inteligencji w procesie tworzenia treści.
Dezinformacja i manipulacja w treściach generowanych przez AI
Dezinformacja i manipulacja w treściach tworzonych przez sztuczną inteligencję stanowią poważne wyzwanie dla społeczeństwa, mediów i instytucji publicznych. Choć algorytmy AI są niezwykle zaawansowane, mogą być wykorzystywane do produkcji fałszywych informacji, które trudno odróżnić od prawdziwych. Szczególnie niebezpieczne są deepfake’i – techniki generowania realistycznych obrazów, nagrań wideo lub audio, które mogą przedstawiać osoby publiczne w zupełnie innym kontekście niż rzeczywistość.
Sztuczna inteligencja generuje dezinformację na wiele sposobów:
- modele językowe potrafią tworzyć teksty oparte na błędnych danych lub wyolbrzymiać istniejące fakty,
- algorytmy mogą automatycznie rozprzestrzeniać fałszywe treści przez media społecznościowe, co prowadzi do kampanii dezinformacyjnych wpływających na wyniki wyborów czy kształtowanie opinii publicznej.
Skutki takich działań są poważne. Fałszywe informacje mogą destabilizować społeczeństwo, podważać zaufanie do mediów oraz wpływać na kluczowe decyzje polityczne i gospodarcze. Dla firm konsekwencje bywają równie dotkliwe – dezinformacja może zaszkodzić reputacji marki lub wprowadzić klientów w błąd co do jakości oferowanych produktów czy usług.
Deepfake’i dodatkowo pogłębiają problem manipulacji. Ta technologia umożliwia tworzenie realistycznych nagrań osób publicznych mówiących rzeczy, których nigdy nie wypowiedziały. Przykładowo, deepfake’i były już wykorzystywane do fałszowania wypowiedzi polityków, co miało wpływ na ich wizerunek i zaufanie społeczne.
Aby przeciwdziałać tym zagrożeniom, niezbędne jest wprowadzenie skutecznych mechanizmów fact-checkingu oraz edukowanie społeczeństwa w zakresie rozpoznawania fałszywych informacji. Kluczowa jest również współpraca między twórcami technologii a instytucjami regulacyjnymi – tylko wspólne działania mogą ograniczyć negatywne skutki dezinformacji i manipulacji generowanych przez AI.
Jak AI tworzy dezinformację?
Sztuczna inteligencja potrafi generować dezinformację, tworząc pozornie wiarygodne treści, które w rzeczywistości są całkowicie fikcyjne. Zjawisko to wynika z tzw. halucynacji, czyli sytuacji, w których modele AI produkują informacje oparte na wzorcach z danych szkoleniowych, a nie na faktach. W ten sposób powstają fałszywe artykuły prasowe, które trudno odróżnić od autentycznych doniesień.
Jednym z głównych problemów jest nadmierna generalizacja. Algorytmy analizują ogromne ilości danych i na ich podstawie tworzą teksty, które często zawierają błędy logiczne lub merytoryczne. Na przykład mogą błędnie łączyć fakty historyczne czy naukowe, co prowadzi do powstawania nieprawdziwych teorii spiskowych lub wprowadzających w błąd wniosków.
Kolejnym wyzwaniem jest brak kontekstu. Modele AI często nie rozumieją pełnego znaczenia słów czy zdarzeń, co skutkuje generowaniem treści mogących wprowadzać odbiorców w błąd. Przykładowo, algorytmy mogą niewłaściwie interpretować dane statystyczne, przedstawiając je w sposób sugerujący fałszywe trendy lub wnioski.
Nie bez znaczenia jest również automatyzacja rozprzestrzeniania dezinformacji. Algorytmy potrafią masowo publikować fałszywe informacje w mediach społecznościowych czy na stronach internetowych. To znacznie przyspiesza ich rozpowszechnianie i utrudnia kontrolę nad tym procesem.
W efekcie sztuczna inteligencja staje się potężnym narzędziem do produkcji treści trudnych do odróżnienia od prawdziwych informacji. To z kolei zwiększa ryzyko manipulacji opinią publiczną oraz destabilizacji społecznej.
Rola deepfake’ów w manipulacji informacjami
Deepfake’i stają się coraz bardziej istotnym narzędziem w manipulowaniu informacjami. Dzięki zaawansowanym technologiom sztucznej inteligencji możliwe jest tworzenie niezwykle realistycznych, ale całkowicie fałszywych obrazów, nagrań wideo czy dźwięków. Pozwala to na przedstawianie znanych osób w sytuacjach, które nigdy nie miały miejsca, co prowadzi do szerzenia dezinformacji i oszustw na masową skalę. Przykłady obejmują fałszywe wypowiedzi polityków, które mogą znacząco wpłynąć na ich wizerunek i zaufanie społeczne.
Jednym z największych wyzwań jest trudność w odróżnieniu autentycznych materiałów od tych wygenerowanych przez AI. Deepfake’i mogą być wykorzystywane do kształtowania opinii publicznej, wpływania na wyniki wyborów czy nawet decyzje gospodarcze. Wystarczy wspomnieć o fałszywych nagraniach liderów państw wypowiadających kontrowersyjne słowa lub celebrytów uczestniczących w fikcyjnych wydarzeniach.
Skutki takich działań są poważne i dalekosiężne. Mogą destabilizować społeczeństwo, podważać zaufanie do mediów oraz wpływać na kluczowe decyzje polityczne i gospodarcze. Dla firm konsekwencje bywają równie dotkliwe – dezinformacja może zaszkodzić reputacji marki lub wprowadzić klientów w błąd co do jakości oferowanych produktów czy usług.
Aby przeciwdziałać tym zagrożeniom, niezbędne jest wprowadzenie skutecznych mechanizmów fact-checkingu oraz edukowanie społeczeństwa w zakresie rozpoznawania fałszywych treści. Kluczowa jest również współpraca między twórcami technologii a instytucjami regulacyjnymi – tylko wspólne działania mogą ograniczyć negatywne skutki manipulacji generowanych przez sztuczną inteligencję.
Konsekwencje szerzenia fałszywych informacji
Sztuczna inteligencja generująca fałszywe informacje stanowi poważne zagrożenie dla społeczeństwa, mediów i instytucji publicznych. Jednym z największych problemów jest erozja zaufania do mediów. Kiedy ludzie nie potrafią odróżnić faktów od fikcji, tracą wiarę w wiarygodność źródeł informacji. To z kolei prowadzi do głębokich podziałów społecznych, gdzie różne grupy opierają się na sprzecznych narracjach, utrudniając dialog i współpracę.
Kolejnym istotnym wyzwaniem jest wpływ dezinformacji na decyzje polityczne i gospodarcze. Fałszywe doniesienia mogą wpływać na wyniki wyborów, kształtować nastroje społeczne lub wprowadzać zamęt w procesach decyzyjnych. Przykładowo, kampanie dezinformacyjne mogą skłonić wyborców do podejmowania decyzji sprzecznych z ich własnymi interesami lub osłabić zaufanie do demokratycznych instytucji.
W świecie biznesu konsekwencje są równie dotkliwe. Dezinformacja może poważnie zaszkodzić reputacji firm, wprowadzić klientów w błąd co do jakości oferowanych produktów czy usług, a nawet wpłynąć na notowania giełdowe. Dlatego przedsiębiorstwa coraz częściej inwestują w narzędzia wykrywania i zwalczania fałszywych treści, aby chronić swoją markę i wiarygodność.
Co więcej, rozprzestrzenianie nieprawdziwych informacji może prowadzić do destabilizacji społecznej. Fałszywe doniesienia o katastrofach naturalnych, epidemiach czy konfliktach zbrojnych mogą wywoływać panikę lub agresję. W skrajnych przypadkach dezinformacja staje się narzędziem propagandy wykorzystywanym w konfliktach militarnych lub atakach terrorystycznych.
Aby przeciwdziałać tym zagrożeniom, niezbędne jest wprowadzenie skutecznych mechanizmów weryfikacji faktów oraz edukowanie społeczeństwa w zakresie krytycznego myślenia i rozpoznawania fałszywych treści. Kluczowa jest również współpraca między twórcami technologii a instytucjami regulacyjnymi – tylko wspólne działania mogą ograniczyć negatywny wpływ dezinformacji generowanej przez sztuczną inteligencję.
Jak AI może generować zmyślone fakty?
Sztuczna inteligencja potrafi generować fikcyjne treści, analizując wzorce w danych szkoleniowych. Zjawisko to, nazywane halucynacjami, polega na tym, że modele AI tworzą informacje, które wydają się wiarygodne, ale są całkowicie zmyślone. Wynika to z faktu, że algorytmy opierają się na statystycznych powiązaniach między słowami i frazami, a nie na rzeczywistych faktach czy wiedzy.
Jednym z kluczowych problemów jest nadmierna generalizacja. AI przetwarza ogromne ilości danych i na ich podstawie generuje treści. Niestety, często prowadzi to do błędów logicznych lub merytorycznych. Przykładowo, model może błędnie łączyć fakty historyczne lub naukowe, tworząc nieprawdziwe teorie spiskowe lub fałszywe wnioski.
Kolejnym wyzwaniem jest ograniczone rozumienie kontekstu. Modele AI często nie potrafią uchwycić pełnego znaczenia słów czy zdarzeń. W efekcie mogą generować treści wprowadzające w błąd. Na przykład algorytmy mogą błędnie interpretować dane statystyczne, sugerując nieistniejące trendy lub fałszywe korelacje.
Co więcej, sztuczna inteligencja może ułatwiać rozprzestrzenianie dezinformacji. Algorytmy są w stanie masowo publikować fałszywe informacje w mediach społecznościowych czy na stronach internetowych. To znacznie przyspiesza ich rozpowszechnianie i utrudnia kontrolę nad tym procesem.
W rezultacie AI staje się potężnym narzędziem do produkcji treści trudnych do odróżnienia od prawdziwych informacji. To zwiększa ryzyko manipulacji opinią publiczną oraz destabilizacji społecznej, co stanowi poważne wyzwanie dla współczesnego świata.
Dwa istotne terminy dla AI: halucynacje i fact-checking
Halucynacje w sztucznej inteligencji to zjawisko, w którym modele AI generują informacje pozornie wiarygodne, ale w rzeczywistości nieprawdziwe lub wprowadzające w błąd. Wynika to z faktu, że algorytmy opierają się na wzorcach wyciągniętych z danych szkoleniowych, a nie na obiektywnej rzeczywistości. Przykładowo, system może wyprodukować tekst zawierający błędne daty historyczne czy fałszywe teorie naukowe, które trudno odróżnić od prawdziwych faktów.
W tym kontekście fact-checking, czyli proces weryfikacji informacji, staje się niezbędnym narzędziem. Jego głównym zadaniem jest ograniczenie ryzyka dezinformacji poprzez dokładne sprawdzanie treści przed ich udostępnieniem. W przypadku sztucznej inteligencji ta praktyka jest szczególnie istotna ze względu na częste występowanie halucynacji.
Te dwa elementy – halucynacje i fact-checking – są ze sobą nierozerwalnie związane. Podczas gdy pierwsze zwiększają prawdopodobieństwo pojawienia się fałszywych informacji, drugie służy jako mechanizm obronny, pozwalający je wykrywać i usuwać. Weźmy za przykład artykuły prasowe tworzone przez AI – bez odpowiedniej kontroli mogą one zawierać poważne błędy lub wprowadzać czytelników w błąd.
Wdrożenie skutecznych metod fact-checkingu ma kluczowe znaczenie dla utrzymania jakości treści oraz zaufania odbiorców. Brak takich procedur zwiększa ryzyko szerzenia się dezinformacji, co może mieć daleko idące konsekwencje społeczne, polityczne czy ekonomiczne. Dlatego tak ważne jest łączenie zaawansowanych technologii AI z solidnymi procesami weryfikacyjnymi.
Wpływ stronniczych wyników generatywnej sztucznej inteligencji
Stronniczość w wynikach generowanych przez sztuczną inteligencję często ma swoje źródło w historycznych i systemowych uprzedzeniach obecnych w danych, na których uczą się algorytmy. Ponieważ AI opiera się na istniejących informacjach, może przejmować tendencyjne wzorce, co prowadzi do powielania tych samych błędów w generowanych treściach. To z kolei wpływa na ich rzetelność i jakość.
Weźmy na przykład modele językowe – mogą one faworyzować określone perspektywy lub pomijać kluczowe konteksty. Jeśli dane szkoleniowe są zdominowane przez informacje z jednego regionu świata, AI może tworzyć treści, które nie odzwierciedlają pełnej różnorodności kulturowej czy społecznej. W efekcie otrzymujemy jednostronne lub niepełne wnioski.
Innym problemem jest stronniczość w interpretacji danych. Algorytmy czasami błędnie łączą fakty lub wyolbrzymiają niektóre aspekty, ignorując inne. Na przykład w analizach statystycznych mogą sugerować fałszywe korelacje między zmiennymi, co prowadzi do niewłaściwych rekomendacji lub decyzji.
Skutki takich uprzedzeń są szczególnie widoczne w kluczowych dziedzinach, takich jak medycyna czy finanse. Nieprawidłowe dane mogą skutkować błędnymi diagnozami medycznymi lub nietrafionymi poradami inwestycyjnymi. W sektorze publicznym stronniczość AI może wpływać na decyzje polityczne i społeczne, pogłębiając istniejące nierówności.
Aby przeciwdziałać tym wyzwaniom, niezbędne jest wprowadzenie mechanizmów audytu danych oraz etycznego projektowania algorytmów. Ważne jest również zwiększenie różnorodności danych szkoleniowych i regularna aktualizacja modeli AI. Tylko w ten sposób można minimalizować ryzyko stronniczości i poprawiać jakość generowanych treści.
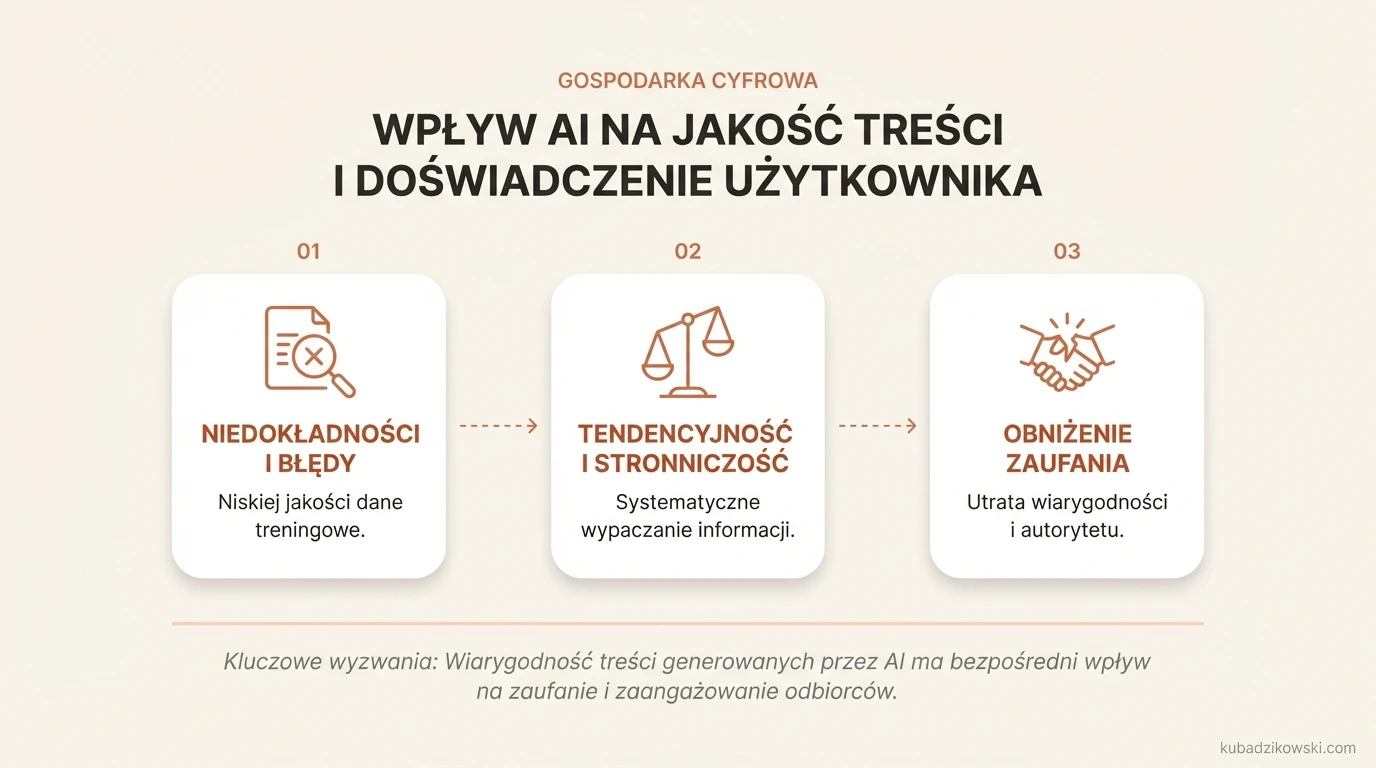
Wpływ na jakość treści i doświadczenie użytkownika
Treści tworzone przez sztuczną inteligencję mają ogromny wpływ na jakość informacji i doświadczenia użytkowników. Jednym z głównych wyzwań jest to, że algorytmy AI mogą generować materiały niedokładne, tendencyjne lub wręcz wprowadzające w błąd. Przyczyną często są niskiej jakości dane treningowe lub błędy w samych modelach. Przykładowo, modele językowe czasem produkują teksty zawierające błędy merytoryczne, co podważa wiarygodność przekazywanych informacji.
Zaufanie odbiorców jest ściśle związane z jakością treści. Gdy użytkownicy natrafiają na nieprecyzyjne lub stronnicze informacje, ich zaufanie do źródła maleje. W obszarach takich jak media czy edukacja może to prowadzić do utraty autorytetu i spadku zaangażowania odbiorców. W sektorach o wysokiej odpowiedzialności, jak medycyna czy finanse, błędy w treściach generowanych przez AI mogą mieć poważne konsekwencje – od błędnych diagnoz po nietrafione decyzje finansowe.
Sposób prezentacji treści również wpływa na doświadczenie użytkownika. Algorytmy często optymalizują teksty pod kątem SEO, co może skutkować nadmiernym uproszczeniem języka lub powtarzaniem kluczowych fraz kosztem wartości merytorycznej. To frustruje osoby poszukujące rzetelnych i szczegółowych informacji.
Personalizacja treści to kolejne wyzwanie. Algorytmy dostosowują przekaz do preferencji użytkownika, co może prowadzić do powstania tzw. bańki informacyjnej – sytuacji, w której odbiorca otrzymuje tylko te informacje, które potwierdzają jego istniejące poglądy. To ogranicza dostęp do różnorodnych perspektyw i wpływa na obiektywizm postrzegania rzeczywistości.
Aby poprawić jakość treści i doświadczenie użytkowników, niezbędne są mechanizmy kontroli jakości oraz regularna aktualizacja modeli AI. Ważna jest również większa transparentność procesu generowania treści oraz edukowanie użytkowników na temat ograniczeń technologii AI. Tylko w ten sposób można minimalizować negatywny wpływ sztucznej inteligencji na jakość informacji i budować trwałe zaufanie odbiorców.
Jak AI wpływa na jakość treści?
Sztuczna inteligencja ma zarówno pozytywne, jak i negatywne skutki dla jakości treści. Z jednej strony, algorytmy potrafią błyskawicznie tworzyć teksty, co znacząco skraca czas produkcji materiałów. Niestety, ich jakość często pozostawia wiele do życzenia. Głównym problemem jest niedokładność – modele AI mogą generować informacje pełne błędów merytorycznych lub logicznych. Wynika to z tzw. halucynacji, czyli sytuacji, w których systemy opierają się na wzorcach z danych szkoleniowych, a nie na rzeczywistych faktach.
Kolejnym wyzwaniem jest stronniczość. Algorytmy uczą się z istniejących zbiorów danych, które mogą zawierać uprzedzenia lub jednostronne perspektywy. W efekcie generowane treści mogą promować określone poglądy lub pomijać istotne konteksty. Przykładowo, w analizach statystycznych AI może sugerować fałszywe związki między zmiennymi, prowadząc do mylnych wniosków.
Wpływ sztucznej inteligencji na jakość treści jest szczególnie widoczny w branżach wymagających precyzji, takich jak medycyna czy finanse. Błędy w generowanych materiałach mogą mieć poważne konsekwencje – od nieprawidłowych diagnoz po nietrafione decyzje finansowe. Dlatego kluczowe jest wprowadzenie mechanizmów fact-checkingu oraz regularna aktualizacja modeli AI.
Doświadczenie użytkowników również ulega zmianie pod wpływem treści tworzonych przez AI. Algorytmy często optymalizują teksty pod kątem SEO, co może prowadzić do nadmiernego uproszczenia języka lub powtarzania kluczowych fraz kosztem wartości merytorycznej. To frustruje osoby poszukujące rzetelnych i szczegółowych informacji.
Personalizacja to kolejny czynnik wpływający na jakość przekazu. Algorytmy dostosowują materiały do preferencji użytkownika, co może prowadzić do powstania tzw. bańki informacyjnej. Odbiorca otrzymuje tylko te informacje, które potwierdzają jego istniejące poglądy, ograniczając dostęp do różnorodnych perspektyw i wpływając na obiektywizm postrzegania rzeczywistości.
Aby poprawić jakość treści i doświadczenie użytkowników, konieczne są mechanizmy kontroli jakości oraz większa transparentność procesu generowania materiałów przez AI. Edukowanie odbiorców na temat ograniczeń technologii również odgrywa kluczową rolę w budowaniu zaufania do sztucznej inteligencji.
Wpływ na wiarygodność i zaufanie użytkowników
Treści tworzone przez sztuczną inteligencję mają ogromne znaczenie dla wiarygodności i zaufania odbiorców. Kiedy informacje są nieprecyzyjne, tendencyjne lub wprowadzające w błąd, użytkownicy tracą zaufanie do źródła, co rodzi sceptycyzm nawet wobec rzetelnych treści. W efekcie mogą zacząć podważać prawdziwość wszystkich przekazów, destabilizując proces komunikacji społecznej.
Jednym z kluczowych problemów jest powielanie błędów przez modele AI. Algorytmy bazują na danych szkoleniowych, które często zawierają nieścisłości lub uprzedzenia. Jeśli model przetwarza teksty z fałszywymi informacjami, może je powielać w nowych treściach, co prowadzi do dalszego rozprzestrzeniania dezinformacji i osłabienia zaufania do technologii.
Kolejnym wyzwaniem jest brak kontekstu. Modele AI często nie rozumieją pełnego znaczenia słów czy zdarzeń, co skutkuje generowaniem mylących treści. Na przykład mogą błędnie interpretować dane statystyczne, sugerując nieistniejące trendy lub fałszywe korelacje. To podważa wiarygodność przekazywanych informacji i wpływa na decyzje użytkowników.
Wpływ na zaufanie jest szczególnie widoczny w sektorach wymagających precyzji, takich jak medycyna czy finanse. Błędy w treściach generowanych przez AI mogą prowadzić do poważnych konsekwencji – od błędnych diagnoz po nietrafione decyzje inwestycyjne. Dlatego kluczowe jest wprowadzenie mechanizmów fact-checkingu oraz regularna aktualizacja modeli AI.
Aby przeciwdziałać tym zagrożeniom, konieczne jest zwiększenie transparentności procesu generowania treści oraz edukowanie użytkowników na temat ograniczeń technologii AI. Tylko w ten sposób można budować trwałe zaufanie do sztucznej inteligencji i minimalizować negatywny wpływ na jakość informacji.
Etyka i odpowiedzialność w generowaniu treści przez AI
Etyka i odpowiedzialność w tworzeniu treści przez sztuczną inteligencję stanowią jedne z najważniejszych wyzwań w rozwoju tej technologii. Jednym z kluczowych problemów jest kwestia odpowiedzialności za materiały generowane przez algorytmy. Gdy AI produkuje dezinformację, szkodliwe treści lub narusza prawa autorskie, kto powinien ponosić konsekwencje? W takich sytuacjach odpowiedzialność może dotyczyć zarówno twórców modeli, jak i osób korzystających z tych narzędzi.
Kolejnym istotnym zagadnieniem jest stronniczość danych, na których uczą się algorytmy. Systemy AI opierają się na istniejących zbiorach informacji, które często odzwierciedlają uprzedzenia kulturowe, rasowe czy płciowe. W efekcie generowane treści mogą utrwalać stereotypy lub marginalizować niektóre grupy społeczne. Przykładowo, modele językowe często preferują perspektywy dominujące, pomijając głosy mniejszości.
Ochrona prywatności to kolejny poważny dylemat etyczny. Sztuczna inteligencja przetwarza ogromne ilości danych osobowych, często bez wyraźnej zgody użytkowników. To rodzi ryzyko nieautoryzowanego wykorzystania wrażliwych informacji oraz pytania o zgodność z przepisami takimi jak RODO.
W kontekście dezinformacji, AI może być narzędziem do produkcji fałszywych wiadomości czy deepfake’ów. Tego typu materiały są trudne do odróżnienia od autentycznych informacji i mogą prowadzić do manipulacji opinią publiczną oraz destabilizacji społecznej. Dlatego tak ważne jest wprowadzenie skutecznych mechanizmów weryfikacji faktów oraz edukowanie społeczeństwa w zakresie krytycznego podejścia do treści.
Odpowiedzialność za materiały generowane przez sztuczną inteligencję obejmuje również aspekty prawne. W przypadku naruszeń praw autorskich lub rozpowszechniania nieetycznych treści konieczne są jasne regulacje określające obowiązki twórców i użytkowników technologii.
Aby przeciwdziałać tym wyzwaniom, niezbędne jest opracowanie etycznych standardów dla projektowania i wykorzystywania AI. Kluczowa jest współpraca między twórcami technologii a instytucjami regulacyjnymi oraz zwiększenie przejrzystości procesu generowania treści przez sztuczną inteligencję. Tylko w ten sposób można minimalizować ryzyka etyczne i budować zaufanie do tej przełomowej technologii przyszłości.
Jakie są wyzwania etyczne związane z AI?
Etyczne dylematy związane ze sztuczną inteligencją często sprowadzają się do problemu stronniczości danych. Algorytmy uczą się na podstawie istniejących zbiorów informacji, które niestety często odzwierciedlają uprzedzenia kulturowe, rasowe czy płciowe. W efekcie generowane przez nie treści mogą nie tylko utrwalać stereotypy, ale także marginalizować głosy mniejszości. Przykładowo, modele językowe częściej promują perspektywy dominujące, ignorując przy tym mniej reprezentowane grupy.
Kolejnym palącym zagadnieniem jest ochrona prywatności. AI przetwarza ogromne ilości danych osobowych, często bez wyraźnej zgody użytkowników. To rodzi poważne ryzyko nieautoryzowanego wykorzystania wrażliwych informacji oraz wątpliwości co do zgodności z przepisami takimi jak RODO. Dobrym przykładem są dane medyczne wykorzystywane do szkolenia modeli bez odpowiednich zabezpieczeń prawnych.
Odpowiedzialność za treści to kolejny kluczowy aspekt etyczny. Gdy AI generuje dezinformację, szkodliwe materiały lub narusza prawa autorskie, pojawia się pytanie: kto powinien ponosić konsekwencje? Odpowiedzialność może spoczywać zarówno na twórcach modeli, jak i na osobach korzystających z tych narzędzi. Na przykład w przypadku rozpowszechniania fałszywych informacji przez chatboty trudno jednoznacznie wskazać winnego.
W kontekście dezinformacji, AI może stać się potężnym narzędziem do produkcji fałszywych wiadomości czy deepfake’ów. Tego typu materiały są trudne do odróżnienia od autentycznych informacji i mogą prowadzić do manipulacji opinią publiczną oraz destabilizacji społecznej. Dlatego tak ważne jest wprowadzenie skutecznych mechanizmów weryfikacji faktów oraz edukowanie społeczeństwa w zakresie krytycznego podejścia do treści.
Aby przeciwdziałać tym wyzwaniom, niezbędne jest opracowanie etycznych standardów dla projektowania i wykorzystywania AI. Kluczowa jest współpraca między twórcami technologii a instytucjami regulacyjnymi oraz zwiększenie przejrzystości procesu generowania treści przez sztuczną inteligencję. Tylko w ten sposób można minimalizować ryzyka etyczne i budować zaufanie do tej przełomowej technologii przyszłości.
Odpowiedzialność za treści generowane przez AI
Odpowiedzialność za treści tworzone przez sztuczną inteligencję to skomplikowane zagadnienie, które wymaga uwzględnienia wielu aspektów. Zarówno twórcy technologii, programiści, jak i użytkownicy mogą w różnym stopniu odpowiadać za błędy lub szkodliwe materiały generowane przez algorytmy AI.
Jednym z kluczowych wyzwań jest określenie odpowiedzialności prawnej. Gdy sztuczna inteligencja rozpowszechnia dezinformację lub narusza prawa autorskie, trudno jednoznacznie wskazać winnego. Czy odpowiedzialność powinna spoczywać na twórcach modeli, firmach korzystających z tych rozwiązań, czy może na samych użytkownikach? Przykładowo, jeśli chatbot przekazuje nieprawdziwe informacje, kto ponosi konsekwencje – dostawca technologii czy osoba korzystająca z narzędzia?
Kolejnym istotnym problemem jest etyka projektowania algorytmów. Modele AI uczą się na podstawie danych szkoleniowych, które często odzwierciedlają uprzedzenia kulturowe, rasowe lub płciowe. W efekcie generowane treści mogą utrwalać stereotypy lub marginalizować niektóre grupy społeczne. Na przykład modele językowe mogą faworyzować dominujące perspektywy, pomijając głosy mniejszości. To rodzi pytania o etyczne standardy w procesie tworzenia i wdrażania takich rozwiązań.
Ochrona prywatności to kolejne poważne wyzwanie. Sztuczna inteligencja przetwarza ogromne ilości danych osobowych, często bez wyraźnej zgody użytkowników. To stwarza ryzyko nieautoryzowanego wykorzystania wrażliwych informacji oraz naruszenia przepisów takich jak RODO. Przykładowo dane medyczne wykorzystywane do szkolenia modeli mogą zostać udostępnione bez odpowiednich zabezpieczeń prawnych.
W kontekście dezinformacji, AI może być wykorzystywana do produkcji fałszywych wiadomości czy deepfake’ów. Tego typu materiały są trudne do odróżnienia od autentycznych informacji i mogą prowadzić do manipulacji opinią publiczną oraz destabilizacji społecznej. Dlatego kluczowe jest wprowadzenie mechanizmów fact-checkingu oraz edukowanie społeczeństwa w zakresie krytycznego podejścia do treści.
Aby przeciwdziałać tym wyzwaniom, niezbędne jest opracowanie etycznych standardów dla projektowania i wykorzystywania AI. Kluczowa jest współpraca między twórcami technologii a instytucjami regulacyjnymi oraz zwiększenie przejrzystości procesu generowania treści przez sztuczną inteligencję. Tylko w ten sposób można minimalizować ryzyka etyczne i budować zaufanie do tej przełomowej technologii przyszłości.
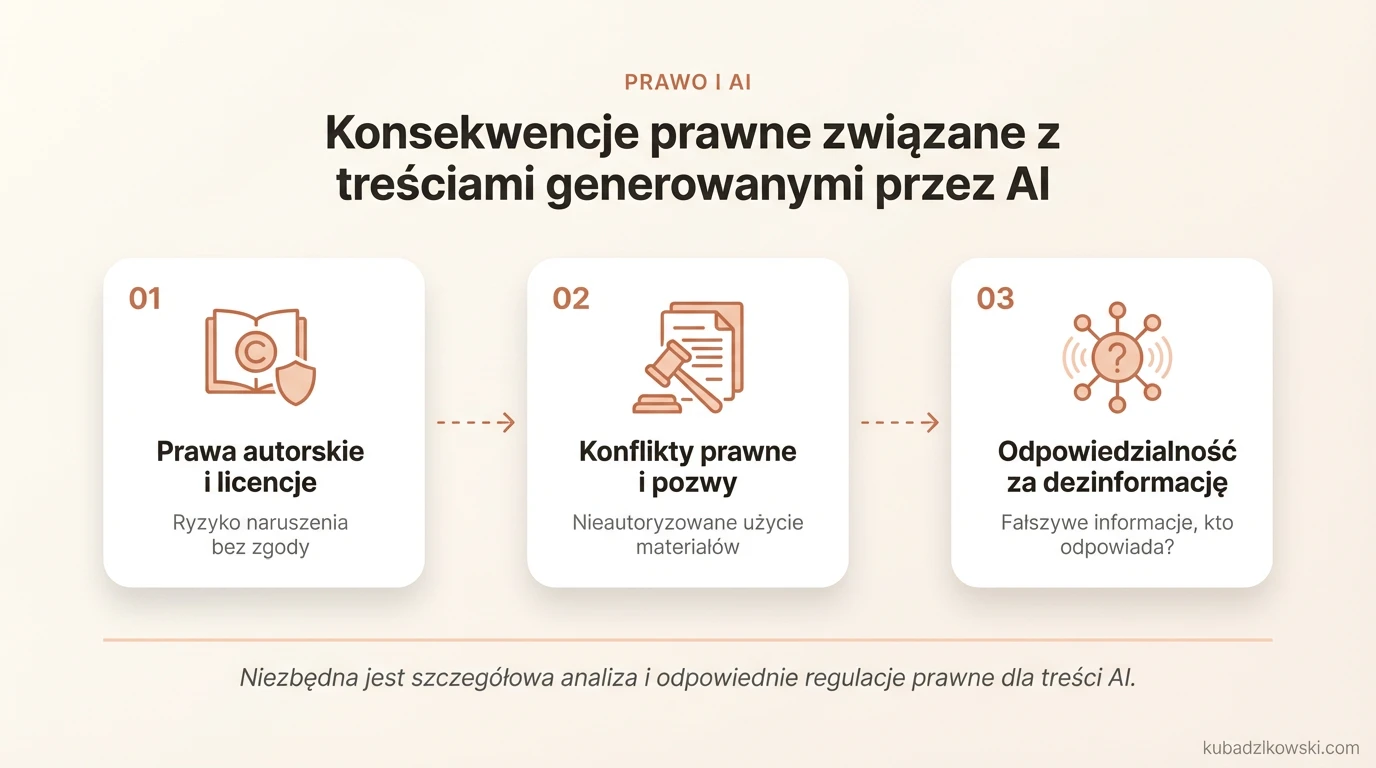
Konsekwencje prawne związane z treściami generowanymi przez AI
Treści tworzone przez sztuczną inteligencję (AI) niosą ze sobą poważne implikacje prawne, wymagające szczegółowej analizy i odpowiednich regulacji. Jednym z kluczowych wyzwań jest kwestia praw autorskich. Algorytmy AI często uczą się na podstawie istniejących dzieł – tekstów, obrazów czy muzyki. Brak odpowiednich licencji lub zgód od właścicieli praw może prowadzić do konfliktów prawnych, czego przykładem są pozwy przeciwko firmom technologicznym za nieautoryzowane wykorzystanie chronionych materiałów.
Kolejnym istotnym problemem jest odpowiedzialność za dezinformację. Gdy AI generuje fałszywe informacje, które trafiają do szerokiego obiegu, pojawia się pytanie o to, kto ponosi konsekwencje. Czy odpowiedzialność spoczywa na twórcach modeli AI, firmach korzystających z technologii, czy może na użytkownikach? W takich sytuacjach mogą być stosowane przepisy dotyczące zniesławienia lub wprowadzania w błąd.
Ochrona danych osobowych to kolejny obszar budzący obawy. Sztuczna inteligencja przetwarza ogromne ilości informacji, w tym dane wrażliwe. Naruszenia przepisów takich jak RODO (Rozporządzenie o Ochronie Danych Osobowych) mogą skutkować wysokimi karami finansowymi oraz utratą zaufania klientów. Przykładem są przypadki wykorzystania danych medycznych do szkolenia modeli bez zgody pacjentów – takie działania mogą prowadzić do poważnych konsekwencji prawnych.
W kontekście deepfake’ów, czyli realistycznych fałszywych nagrań tworzonych przez AI, pojawiają się dodatkowe wyzwania. Technologia ta może być wykorzystywana do oszustw finansowych, szantażu czy manipulacji opinią publiczną. Wiele krajów pracuje nad przepisami mającymi na celu kontrolę tworzenia i dystrybucji tego typu materiałów.
Sprawy sądowe związane z treściami generowanymi przez AI już mają miejsce na całym świecie. W Stanach Zjednoczonych toczą się procesy dotyczące naruszeń praw autorskich przez duże firmy technologiczne wykorzystujące dzieła artystyczne do szkolenia swoich modeli. W Europie coraz częściej rozpatrywane są kwestie związane z ochroną prywatności i zgodnością z RODO.
Aby przeciwdziałać tym zagrożeniom, niezbędne jest wprowadzenie przejrzystych regulacji określających zasady korzystania z technologii AI oraz zakres odpowiedzialności za jej działania. Kluczowa jest również współpraca między twórcami technologii a instytucjami regulacyjnymi w celu zapewnienia zgodności z obowiązującym prawem i minimalizacji ryzyka naruszeń prawnych.
Jakie są ryzyka prawne związane z AI?
Sztuczna inteligencja wiąże się z szeregiem wyzwań prawnych, które obejmują różne obszary. Jednym z najważniejszych jest kwestia naruszeń praw autorskich. Modele AI często uczą się na podstawie chronionych materiałów, co może prowadzić do konfliktów prawnych, szczególnie gdy właściciele praw nie wyrazili na to zgody. Przykładem są liczne pozwy kierowane przeciwko firmom technologicznym za wykorzystanie dzieł artystycznych lub literackich bez odpowiednich zezwoleń.
Kolejnym problemem jest odpowiedzialność za treści generowane przez systemy AI. Gdy te narzędzia produkują fałszywe informacje, które trafiają do publicznego obiegu, pojawia się pytanie o to, kto powinien ponosić konsekwencje – twórcy modeli, firmy korzystające z technologii czy użytkownicy końcowi? W takich sytuacjach mogą być stosowane przepisy dotyczące zniesławienia lub wprowadzania w błąd.
Ochrona danych osobowych to kolejny kluczowy aspekt. Sztuczna inteligencja przetwarza ogromne ilości informacji, w tym dane wrażliwe. Naruszenia przepisów, takich jak RODO, mogą skutkować nie tylko wysokimi karami finansowymi, ale także utratą zaufania klientów. Przykładowo wykorzystanie danych medycznych do szkolenia modeli bez zgody pacjentów może prowadzić do poważnych konsekwencji prawnych i etycznych.
Deepfake’i stanowią kolejne poważne wyzwanie. Ta technologia może być wykorzystywana do oszustw finansowych, szantażu czy manipulacji opinią publiczną. Wiele krajów pracuje nad nowymi regulacjami mającymi na celu kontrolę tworzenia i dystrybucji tego typu materiałów.
Sprawy sądowe związane z treściami generowanymi przez AI już mają miejsce na całym świecie. W Stanach Zjednoczonych toczą się procesy dotyczące naruszeń praw autorskich przez duże firmy technologiczne wykorzystujące dzieła artystyczne do szkolenia swoich modeli. W Europie coraz częściej rozpatrywane są kwestie związane z ochroną prywatności i zgodnością z RODO.
Aby przeciwdziałać tym zagrożeniom, konieczne jest wprowadzenie przejrzystych regulacji określających zasady korzystania z technologii AI oraz zakres odpowiedzialności za jej działania. Kluczowa jest również współpraca między twórcami technologii a instytucjami regulacyjnymi w celu zapewnienia zgodności z obowiązującym prawem i minimalizacji ryzyka naruszeń prawnych.
Przypadki sądowe związane z dezinformacją AI
Sprawy sądowe związane z dezinformacją generowaną przez sztuczną inteligencję (AI) przybierają na sile, co wynika z rosnącej liczby przypadków, w których osoby prywatne lub firmy dochodzą odszkodowań za szkody spowodowane fałszywymi informacjami tworzonymi przez algorytmy. Jednym z najbardziej głośnych przykładów są pozwy przeciwko gigantom technologicznym za rozpowszechnianie nieprawdziwych treści, które naruszyły reputację lub interesy finansowe poszkodowanych. W takich sytuacjach kluczowe staje się ustalenie, kto powinien ponosić odpowiedzialność – czy twórcy modeli AI, firmy korzystające z tych rozwiązań, czy może użytkownicy końcowi.
W Stanach Zjednoczonych coraz więcej procesów dotyczy naruszeń praw autorskich. Wielkie korporacje wykorzystują dzieła artystyczne do trenowania swoich systemów AI bez zgody twórców, co budzi kontrowersje i prowadzi do sporów prawnych. Z kolei w Europie uwagę przyciągają sprawy związane z ochroną prywatności i zgodnością z RODO, zwłaszcza gdy dane osobowe są przetwarzane bez odpowiednich podstaw prawnych. Przykładem może być wykorzystanie wrażliwych informacji medycznych do szkolenia algorytmów bez zgody pacjentów.
Deepfake’i stanowią kolejne poważne wyzwanie dla systemu prawnego. Ta technologia może być wykorzystywana do oszustw finansowych, szantażu czy manipulowania opinią publiczną. Wiele państw pracuje nad nowymi przepisami mającymi na celu kontrolę tworzenia i dystrybucji tego typu materiałów. Ofiary coraz częściej występują na drogę sądową, domagając się odszkodowań za naruszenie dóbr osobistych poprzez fałszywe nagrania.
W Polsce również obserwujemy wzrost liczby spraw związanych z dezinformacją generowaną przez AI. Przykładem są pozwy przeciwko platformom społecznościowym za niekontrolowane rozpowszechnianie fałszywych informacji tworzonych przez algorytmy. W takich przypadkach kluczowe jest udowodnienie winy oraz określenie zakresu odpowiedzialności platform za treści publikowane przez ich użytkowników.
Aby skutecznie przeciwdziałać tym zagrożeniom, niezbędne jest wprowadzenie przejrzystych regulacji określających zasady korzystania z technologii AI oraz zakres odpowiedzialności za jej działania. Kluczowa jest również współpraca między twórcami rozwiązań a instytucjami regulacyjnymi, aby zapewnić zgodność z obowiązującym prawem i minimalizować ryzyko przyszłych naruszeń prawnych.


