

Wybór między URL-ami bezwzględnymi a względnymi nie sprowadza się do sporu o „lepsze SEO”, tylko do kwestii bezpieczeństwa i konsekwencji we wdrożeniu. Wyszukiwarki radzą sobie z oboma formatami, natomiast źle znoszą nieporządek w canonicalach, linkowaniu wewnętrznym, sitemapach i przekierowaniach. W praktyce kluczowe jest to, czy wszystkie newralgiczne miejsca wskazują jedną, docelową wersję adresu. Gdy ten sam zasób raz pojawia się pod jednym hostem, raz pod innym, raz z http, raz z https albo z odmiennymi ścieżkami, szybko wychodzą problemy z duplikacją i rozjechanymi sygnałami. Z tego powodu decyzję warto podejmować nie w teorii, lecz na poziomie szablonów, CMS-a, frontendu i eksportów. Temat nabiera szczególnej wagi przy migracjach, stagingu, wielu domenach oraz serwisach z rozbudowaną logiką renderowania.
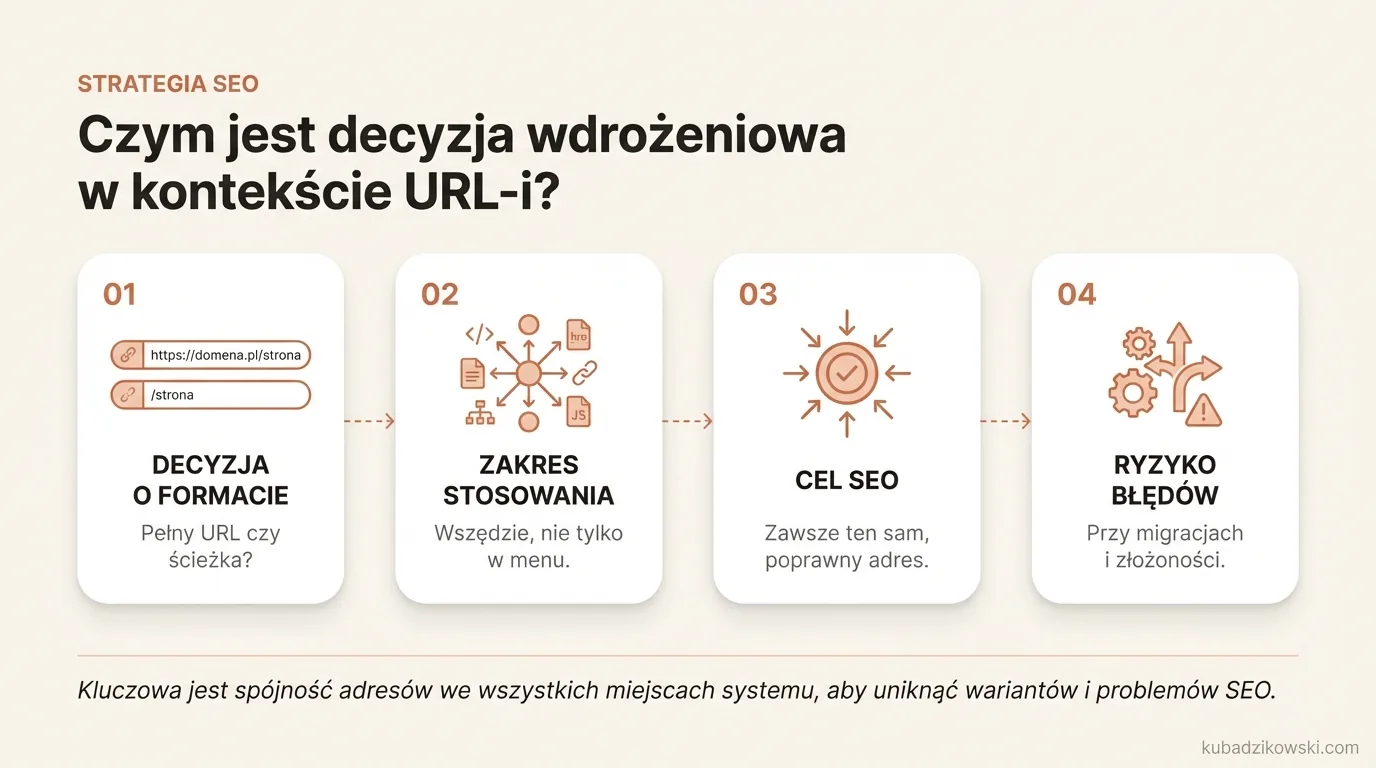
Czym jest decyzja wdrożeniowa w kontekście URL-i?
To ustalenie, w jaki sposób serwis ma tworzyć adresy w różnych miejscach: jako pełne URL-e z protokołem i domeną albo jako ścieżki zależne od aktualnego adresu. Nie dotyczy to wyłącznie linków w menu, ale także canonicali, hreflangów, sitemap, breadcrumbs, linków w treści, komponentów JavaScript, feedów oraz maili. W SEO znaczenie ma nie tyle sam zapis URL-a, ile to, czy w każdym miejscu wskazujesz tę samą, poprawną wersję adresu.
Najczęściej kłopot nie wychodzi na stronie głównej, tylko w bardziej złożonych scenariuszach technicznych. Widać to przy migracji domeny, przejściu z http na https, działaniu kilku subdomen, środowiskach stagingowych oraz wtedy, gdy linki generują różne moduły niezależnie od siebie. Jeśli każdy element trzyma się innej logiki, łatwo o warianty adresów, które zaczynają rywalizować między sobą.
Decyzja wdrożeniowa powinna więc obejmować cały system, a nie pojedynczy znacznik. Warto prześledzić, skąd dokładnie biorą się adresy w HTML-u źródłowym, po renderowaniu JS oraz w plikach eksportowych. Największe ryzyko pojawia się wtedy, gdy miesza się kilka sposobów generowania URL-i bez jednego, wspólnego standardu.
Aktualne praktyki w użyciu URL-i bezwzględnych i względnych
Obecnie najczęściej przyjmuje się, że URL-e bezwzględne są bezpiecznym standardem wszędzie tam, gdzie adres ma działać poza bieżącym kontekstem strony. Dotyczy to w szczególności canonicali, hreflangów, map witryny, danych Open Graph, feedów, maili oraz innych eksportów. W tych miejscach pełny adres ogranicza ryzyko błędnego odczytania hosta, protokołu lub ścieżki.
URL-e względne wciąż mogą działać poprawnie w linkowaniu wewnętrznym jednego serwisu, ale pod warunkiem, że środowisko jest pod kontrolą. Taki wybór bywa sensowny, gdy strona działa na jednym hoście, nie ma złożonych punktów wejścia, a logika generowania ścieżek pozostaje spójna w całym systemie. Względne ścieżki sprawdzają się głównie tam, gdzie kontekst dokumentu jest zawsze przewidywalny.
W praktyce kłopoty najczęściej wychodzą na jaw w serwisach z base href, reverse proxy, wieloma hostami, katalogami językowymi, aplikacjami SPA oraz w środowiskach testowych sklonowanych z produkcji. W takich konfiguracjach adres względny potrafi wskazać inne miejsce, niż przewidywał zespół wdrożeniowy. Nie zawsze daje to błąd widoczny od ręki, ale skutecznie komplikuje crawling, audyt i rozpoznanie duplikacji.
Coraz rzadziej ma też uzasadnienie stosowanie adresów zależnych od protokołu w formie //example.com. Dawniej bywało to wygodne technicznie, dziś najczęściej tylko utrudnia analizę zasobów i ocenę bezpieczeństwa. Jeśli chcesz uprościć SEO i utrzymanie serwisu, wybierz jeden jawny standard adresów zamiast kilku „prawie poprawnych” wariantów.
Jak poprawnie wdrożyć URL-e w serwisie internetowym?
Poprawne wdrożenie URL-i sprowadza się do ustalenia jednego standardu adresowania dla każdego typu użycia oraz dopilnowania, aby cały serwis konsekwentnie go generował. Na start warto zinwentaryzować wszystkie miejsca, w których powstają adresy: menu, breadcrumbs, paginację, linki w treści, canonicale, hreflangi, sitemapę, dane strukturalne, moduły JavaScript, feedy i maile systemowe. Bez takiej listy łatwo naprawić jeden obszar, a zostawić drugi, który nadal wysyła do Google sprzeczne sygnały. Najczęstszy problem nie wynika z samego typu URL-a, tylko z tego, że różne części serwisu generują różne wersje tego samego adresu.
Po inwentaryzacji trzeba sprawdzić, jak te adresy zachowują się w realnych scenariuszach. Liczy się host, protokół, końcowy slash, wielkość liter, parametry, ścieżki względne zależne od katalogu oraz to, co dzieje się po wejściu na niestandardowe URL-e. Dobrze testować nie tylko stronę główną i typowe podstrony, ale również paginację, filtry, wersje językowe, trasy SPA oraz adresy z UTM-ami. Właśnie tam najczęściej ujawniają się błędy, takie jak źle wyliczona ścieżka względna albo canonical wskazujący inną wersję hosta.
Następnie trzeba zdecydować, gdzie stosować adresy bezwzględne, a gdzie ewentualnie względne. W praktyce standard ustala się osobno dla linkowania wewnętrznego, osobno dla znaczników SEO i osobno dla eksportów poza stronę. Dla elementów interpretowanych poza bieżącym kontekstem dokumentu trzeba używać finalnych, pełnych adresów, a nie ścieżek zależnych od miejsca osadzenia. Dzięki temu canonical, hreflang czy sitemap nie zmienią znaczenia po wdrożeniu na innym hoście, przez proxy albo na kopii stagingowej.
Samo wdrożenie zwykle oznacza poprawki równolegle w kilku warstwach. Trzeba ujednolicić helpery CMS, logikę szablonów, komponenty frontendowe, generatory map witryny oraz miejsca, w których aplikacja składa adresy po stronie klienta. Jeżeli część linków buduje backend, a część frontend, oba źródła powinny opierać się na tych samych regułach. Mieszanie reguł generowania URL-i jest częstą przyczyną błędów, które widać dopiero po migracji lub zmianie domeny.
Na finiszu potrzebne są normalizacja i walidacja. Trzeba ustawić przekierowania na jedną, docelową wersję, usunąć odnośniki prowadzące do URL-i po przekierowaniu oraz sprawdzić, czy kod źródłowy i wyrenderowany DOM wskazują te same adresy. Dobry test po wdrożeniu to crawl serwisu, kontrola sitemap, podgląd znaczników SEO oraz ręczna weryfikacja kilku bardziej wymagających scenariuszy wejścia. Jeżeli po wdrożeniu jeden zasób nadal jest dostępny pod różnymi hostami, protokołami lub ścieżkami, problem wciąż pozostaje nierozwiązany.
- Sprawdź, czy canonical konsekwentnie wskazuje docelowy adres 200, a nie URL po przekierowaniu.
- Zweryfikuj, czy hreflangi stosują pełne adresy i nie mieszają środowisk.
- Upewnij się, że sitemap zawiera tę samą wersję URL-i co linkowanie wewnętrzne.
- Przetestuj głębokie podstrony, filtry, paginację oraz warianty z parametrami.
- Zestaw HTML źródłowy z wersją renderowaną przez JavaScript.

Co wybrać: URL-e bezwzględne czy względne?
W większości serwisów najbezpieczniej przyjąć URL-e bezwzględne jako standard dla elementów krytycznych dla SEO oraz dla wszystkich adresów używanych poza bieżącą stroną. Dotyczy to w szczególności canonicali, hreflangów, map witryny, danych Open Graph, feedów, maili transakcyjnych i eksportów. W tych obszarach pełny adres daje większą pewność, bo działa niezależnie od kontekstu dokumentu, hosta i sposobu renderowania. Dzięki temu spada ryzyko, że ten sam zasób zostanie opisany kilkoma wariantami URL-a.
URL-e względne można rozważyć w linkowaniu wewnętrznym w obrębie jednego serwisu, ale wyłącznie w środowisku, które jest dobrze opanowane. Ma to sens, gdy serwis działa na jednym hoście i nie pojawiają się problemy z base href, reverse proxy, wersjami stagingowymi ani niestandardowym routingiem. W praktyce bywa to wygodne dla deweloperów, jednak wymaga większej dyscypliny technicznej. Gdy infrastruktura jest złożona, zysk z krótszych ścieżek zwykle nie równoważy ryzyka pomyłek.
Najgorszym scenariuszem jest przypadkowe mieszanie obu form w tych samych typach elementów. Gdy część canonicali jest bezwzględna, część względna, a linki wewnętrzne dodatkowo kierują na adresy po przekierowaniu, audyt i diagnoza szybko robią się mało czytelne. Spójność ma większe znaczenie niż sama preferencja jednego formatu. Im mniej odstępstw od reguły, tym łatwiej utrzymać poprawne sygnały po zmianach technicznych.
W serwisach wielodomenowych, wielojęzycznych albo opartych na kilku punktach wejścia aplikacji wybór powinien być prosty: stosuj adresy bezwzględne wszędzie tam, gdzie błąd może zmienić interpretację adresu. To samo dotyczy projektów z częstymi migracjami, stagingiem i frontendem renderowanym częściowo po stronie klienta. Jeżeli adres ma pozostać jednoznaczny po zmianie kontekstu, użyj formy bezwzględnej. URL względny zostaw tylko tam, gdzie faktycznie kontrolujesz cały mechanizm jego rozwiązywania.
- Stosuj URL-e bezwzględne w: canonicalach, hreflangach, sitemapach, feedach, mailach, Open Graph oraz eksportach.
- URL-e względne zostaw wyłącznie dla nawigacji wewnętrznej w ramach jednego, stabilnego hosta.
- Unikaj adresów zależnych od protokołu w zapisie //example.com, bo obecnie częściej utrudniają diagnostykę, niż realnie pomagają.
- Po wdrożeniu obserwuj adresy stagingowe, linki prowadzące przez przekierowania oraz rozbieżności między HTML-em a renderem JS.
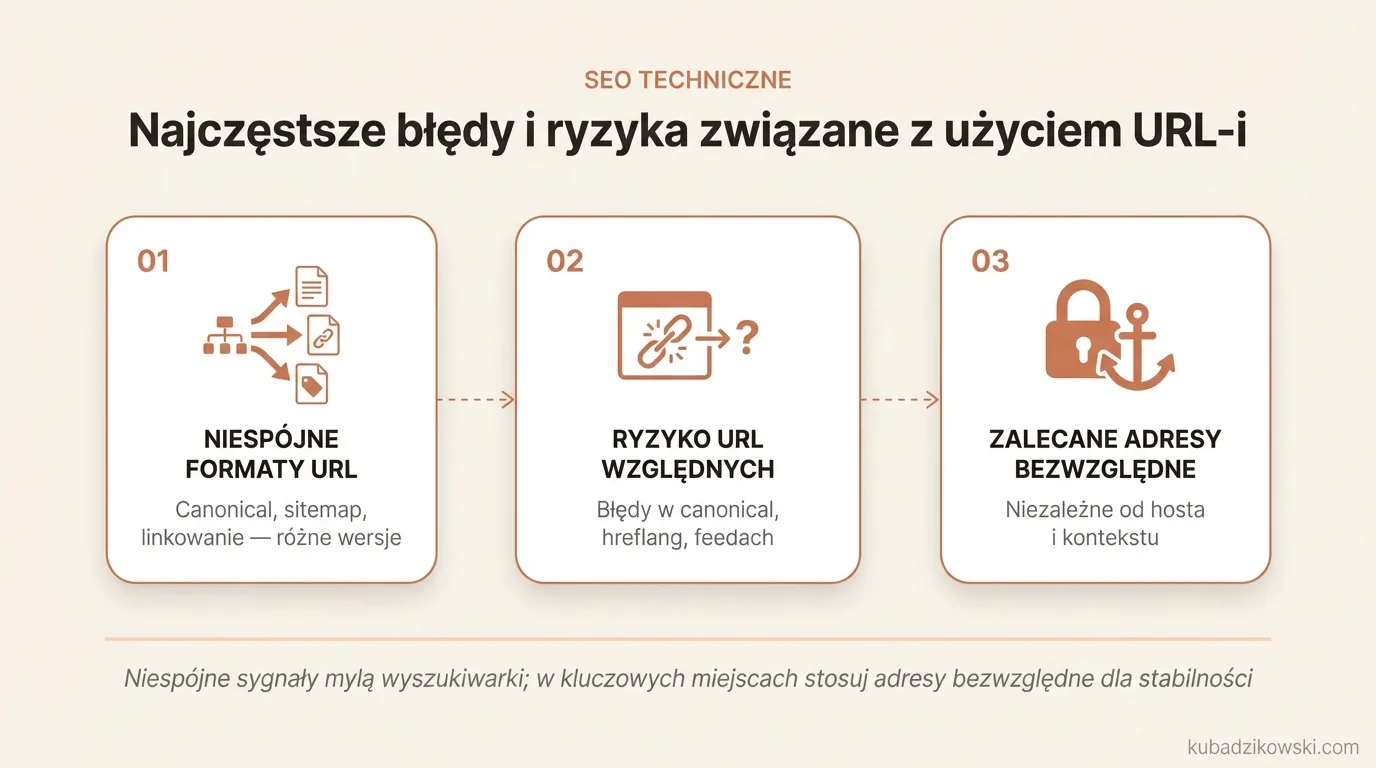
Najczęstsze błędy i ryzyka związane z użyciem URL-i
Najczęściej problemem jest mieszanie formatów adresów tam, gdzie wszystkie elementy powinny wskazywać jedną wersję URL-a. Zwykle nie zaczyna się to od linku w menu, tylko od sytuacji, w której canonical pokazuje jeden adres, sitemapa drugi, a linkowanie wewnętrzne trzeci. Gdy sygnały kanoniczne nie są spójne, wyszukiwarka dostaje kilka wersji tej samej strony zamiast jednej preferowanej.
Duże ryzyko pojawia się wtedy, gdy względne URL-e trafiają do elementów działających poza bieżącym kontekstem dokumentu. Dotyczy to przede wszystkim canonicali, hreflangów, map witryny, feedów, danych Open Graph oraz maili systemowych. W tych miejscach bezpieczniejszym standardem są adresy bezwzględne, bo nie zależą od aktualnego hosta, katalogu ani sposobu renderowania strony.
Częsty błąd techniczny to założenie, że względna ścieżka zawsze złoży się poprawnie. W praktyce potrafią ją zepsuć między innymi źle ustawiony base href, reverse proxy, trasy aplikacji SPA, wejście na głębszy poziom katalogów czy dodatkowe parametry w adresie. Jeśli serwis działa na wielu hostach, subdomenach albo w wersjach językowych, względne ścieżki szybciej prowadzą do błędnych lub nieoczekiwanych adresów.
Osobna grupa problemów wychodzi na jaw dopiero przy migracji domeny, zmianie protokołu albo pracy na środowiskach testowych. Wtedy do indeksowalnych miejsc potrafią trafić adresy stagingowe, stare hosty lub linki, które najpierw kierują na przekierowanie, a dopiero potem na wersję docelową. Niezbyt dobrym pomysłem są też adresy zależne od protokołu w formie //example.com, bo dziś zwykle nie dają korzyści, a utrudniają diagnozę zasobów i bezpieczeństwa.
Jak monitorować i weryfikować poprawność URL-i po wdrożeniu?
Poprawność URL-i po wdrożeniu najlepiej sprawdzać przez cykliczny crawl serwisu, kontrolę kodu źródłowego oraz weryfikację wersji renderowanej w przeglądarce. Sam podgląd kilku stron nie wystarczy, bo część błędów ujawnia się dopiero na paginacji, filtrach, głębokich podstronach i wariantach językowych. Trzeba sprawdzać nie tylko to, co widać w HTML-u, ale też to, co ostatecznie generują skrypty i komponenty frontendowe.
- czy canonicale, hreflangi i sitemapy wskazują finalne adresy docelowe, bez zmiany hosta, protokołu i bez zbędnych przekierowań,
- czy linki wewnętrzne prowadzą bezpośrednio do właściwych URL-i, a nie do wersji pośrednich,
- czy w indeksowalnych miejscach nie przewijają się adresy stagingowe, testowe albo stare domeny,
- czy względne ścieżki zachowują się poprawnie po wejściu na głębsze adresy, strony z parametrami oraz trasy aplikacji SPA,
- czy kod źródłowy i wyrenderowany DOM nie prezentują dwóch wariantów tego samego linku.
W praktyce opłaca się sprawdzać również nietypowe scenariusze wejścia, bo to one najczęściej wyciągają na wierzch potknięcia w logice adresowania. Warto przejrzeć stronę z UTM-ami, widok z filtrami, paginację, wersję językową oraz podstrony osadzone głębiej w strukturze. Gdy względne URL-e zaczynają składać ścieżki inaczej, niż zakładano, źródła problemu zwykle należy szukać w szablonie, routerze albo w ustawieniach bazowego adresu.
Po wdrożeniu monitoring nie powinien kończyć się na jednorazowym audycie. Każda zmiana szablonu, migracja, nowy moduł JS, wersja mobilna albo aktualizacja CMS może ponownie rozregulować generowanie adresów. Najlepsza praktyka to wracać do tych samych kontroli po każdej większej zmianie technicznej, zanim błędne URL-e zaczną się propagować po całym serwisie.


