

Crawling to etap, w którym Google odkrywa adresy URL, pobiera ich zawartość i ocenia, czy oraz kiedy ponownie do nich wrócić. Dla właściciela strony nie jest to techniczna ciekawostka, lecz czynnik realnie wpływający na widoczność kluczowych podstron. Gdy Google nie natrafi na stronę, nie odczyta jej poprawnie albo poświęci budżet na nieistotne adresy, rezultaty SEO będą ograniczone. Sama obecność strony w internecie nie oznacza jeszcze, że Google sprawnie ją crawluje i zaindeksuje. W praktyce źródłem kłopotów najczęściej są błędy techniczne, słabe linkowanie wewnętrzne oraz bałagan w adresach URL. Warto podejść do tematu operacyjnie, ponieważ wiele usprawnień da się wdrożyć szybko, bez przebudowy całego serwisu.
Czym jest crawling i jak działa w praktyce?
Crawling polega na tym, że Google znajduje adresy URL, odwiedza je, odczytuje treść i decyduje, co zrobić z nimi dalej. Robot trafia na strony przede wszystkim dzięki linkom wewnętrznym, mapom XML, wcześniejszym wizytom oraz sygnałom zewnętrznym. Jeżeli ważna podstrona nie ma sensownego podlinkowania, może być odkrywana bardzo wolno albo wcale. Sitemap pomaga, ale nie zastępuje dobrej architektury linków wewnętrznych.
Po wykryciu adresu Google weryfikuje, czy może go pobrać, oraz jak odpowiada serwer. Na tym etapie znaczenie mają między innymi robots.txt, meta robots, kod HTTP, przekierowania, czas odpowiedzi oraz dostęp do plików CSS i JavaScript. Gdy strona zwraca błędy 5xx, wpada w pętle przekierowań albo wygląda jak soft 404, robot traci zasoby i trudniej mu skutecznie przejść dalej.
Następnie Google analizuje sygnały techniczne i próbuje ustalić, która wersja adresu jest właściwa. Pod uwagę brany jest canonical, spójność wersji HTTP i HTTPS, warianty z www i bez www, a także to, czy sygnały nie są ze sobą sprzeczne. Jedna strona nie powinna jednocześnie sugerować indeksacji i blokować jej innym sygnałem.
Jeśli treść lub linki są generowane przez JavaScript, Google może dodatkowo wyrenderować stronę. Ma to znaczenie, ponieważ część serwisów pokazuje kluczową treść dopiero po wykonaniu skryptów albo po interakcji użytkownika. W praktyce oznacza to, że ciężki front-end potrafi opóźnić odkrywanie linków i indeksację treści, nawet jeśli strona „działa” z perspektywy człowieka.
Na końcu Google rozstrzyga, czy dany URL dodać do indeksu, z jakim adresem kanonicznym go powiązać oraz kiedy ponownie go odwiedzić. Nie każda pobrana strona trafia do indeksu, bo liczy się także jej unikalność, jakość i użyteczność. Dlatego crawling warto traktować jako początek procesu, a nie jego finał.

Jakie czynniki wpływają na efektywność indeksacji przez Google?
O skuteczności indeksacji decyduje przede wszystkim to, czy Google bez trudu dociera do kluczowych podstron, może je pobrać bez przeszkód i otrzymuje spójne sygnały techniczne. Największą rolę odgrywają linkowanie wewnętrzne, jakość odpowiedzi serwera, ład w adresach URL oraz wartość samej treści. Gdy te obszary kuleją, nawet prawidłowo przygotowana mapa XML nie usunie przyczyny problemu.
Wiele zależy też od tego, czy serwis nie przepala budżetu crawlowania na podstrony zbędne. Najczęstsze źródła strat to filtry, sortowania, parametry w URL, wyniki wyszukiwania wewnętrznego, duplikaty oraz niekontrolowana paginacja. Im więcej technicznych lub powielonych adresów odwiedza robot, tym mniej uwagi może poświęcić stronom naprawdę ważnym biznesowo. Jest to szczególnie istotne w e-commerce, portalach i dużych serwisach, gdzie treści często się zmieniają.
Nie bez znaczenia pozostaje kondycja techniczna witryny. Powtarzające się błędy 5xx, timeouty, łańcuchy przekierowań, źle ustawione canonicale oraz konflikty między noindex a linkowaniem osłabiają efektywność crawlu i indeksacji. W takiej sytuacji Google uznaje stronę za mniej przewidywalną i trudniejszą w przetwarzaniu.
Dużą różnicę robi również sposób podawania treści. Google potrafi renderować JavaScript, ale nie zawsze dzieje się to od ręki i nie każda treść doładowywana po stronie klienta będzie równie łatwa do odkrycia. Jeśli kluczowy tekst i linki są dostępne od razu w HTML, Google zwykle szybciej je odczyta i lepiej zrozumie strukturę strony.
Na indeksację wpływa także jakość pojedynczej podstrony. Google nie indeksuje automatycznie wszystkiego, co uda mu się pobrać, bo bierze pod uwagę unikalność, użyteczność oraz spójność z resztą serwisu. Strony cienkie treściowo, prawie identyczne lub tworzone wyłącznie pod warianty filtrów często są crawl-owane, ale nie wnoszą realnej wartości do indeksu.
W diagnostyce najlepiej opierać się na danych, a nie na przypuszczeniach. Search Console sygnalizuje problemy z indeksacją i część sygnałów technicznych, jednak dopiero logi serwera pokazują, które URL-e Google faktycznie odwiedza i z jaką częstotliwością. Jeśli chcesz poprawić crawling, zacznij od analizy logów, linkowania wewnętrznego oraz jakości sitemap XML.
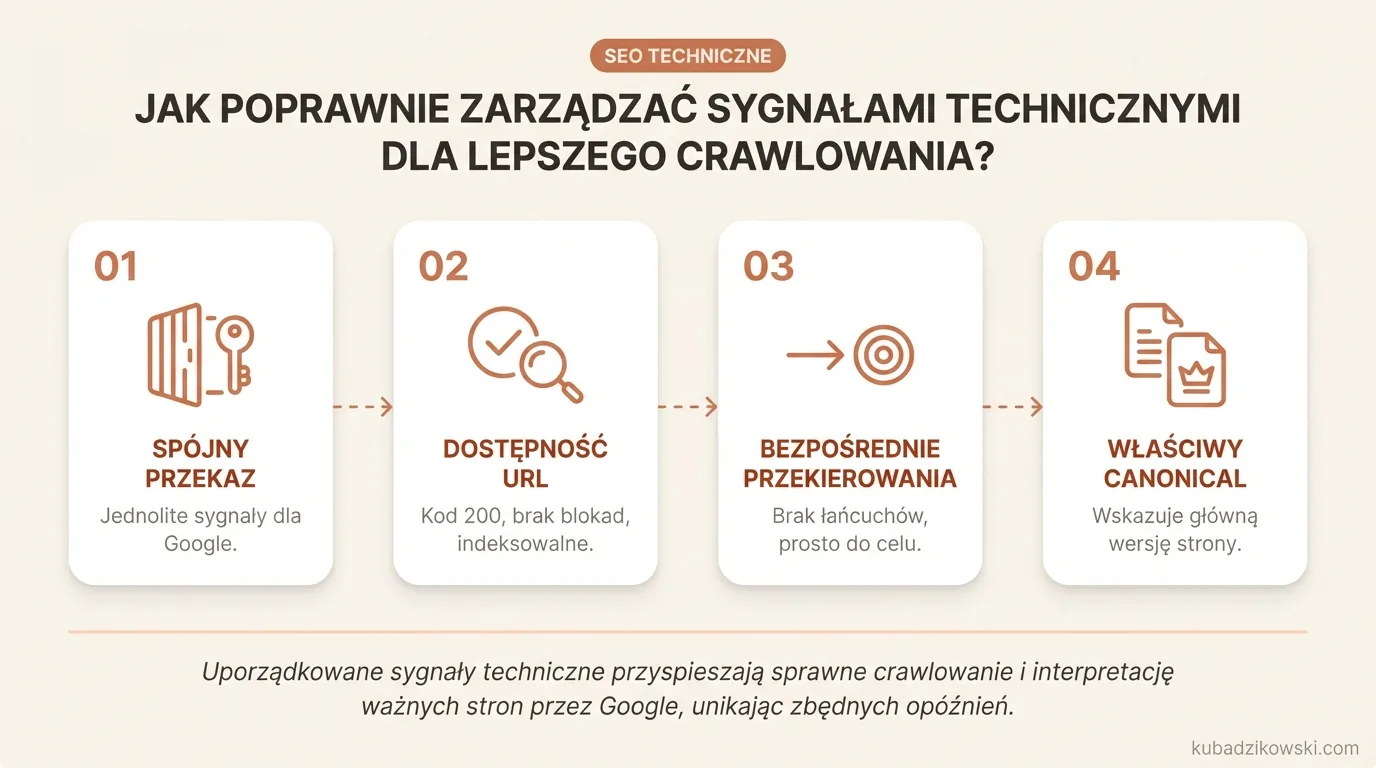
Jak poprawnie zarządzać sygnałami technicznymi dla lepszego crawlowania?
Poprawne zarządzanie sygnałami technicznymi polega na tym, aby Google dostawał jeden, spójny przekaz: które URL-e może pobrać, które może indeksować i która wersja strony jest właściwa. Najwięcej kłopotów wynika nie z pojedynczej usterki, lecz z rozjazdów między robots.txt, meta robots, canonicalem, przekierowaniami oraz strukturą adresów. Gdy te sygnały mówią różne rzeczy, Google traci czas na interpretację zamiast sprawnie crawlować ważne strony.
Na początek uporządkuj dostępność adresów. Strona, która ma być widoczna, powinna zwracać kod 200, nie może być blokowana w robots.txt i nie powinna mieć meta robots z noindex. Jeżeli istotny URL przekierowuje, zadbaj o to, by przekierowanie prowadziło prosto do wersji docelowej, bez łańcucha kilku pośrednich kroków.
Canonical powinien wskazywać wariant, który rzeczywiście chcesz promować jako główny. Ma to szczególne znaczenie przy filtrach, parametrach, wersjach z ukośnikiem i bez ukośnika, HTTP i HTTPS oraz www i non-www. Canonical nie posprząta bałaganu w architekturze URL-i, ale użyty z głową ogranicza duplikację i ułatwia Google wybór właściwej strony.
Robots.txt lepiej traktować jako narzędzie do kontrolowania dostępu, a nie sposób na załatwienie wszystkich kłopotów z indeksacją. Zablokowanie URL-a w robots.txt może uniemożliwić Google odczyt treści, ale nie zawsze sprawia, że taki adres znika z wyników. Jeśli zależy Ci na tym, by strona nie trafiła do indeksu, najczęściej potrzebujesz URL-a dostępnego dla bota z noindex albo poprawnego przekierowania do wersji docelowej.
W serwisach opartych na JavaScript dopilnuj, aby kluczowa treść i linki były osiągalne bez ciężkiego renderowania po stronie klienta. Google potrafi renderować JS, jednak nie zawsze dzieje się to od razu i nie każda implementacja działa bez zarzutu. Gdy menu, tekst lub odnośniki do ważnych podstron pojawiają się dopiero po interakcji użytkownika, odkrywanie tych URL-i będzie wolniejsze albo niepełne.
Zwróć uwagę również na spójność sygnałów pomocniczych. Sitemapa XML powinna zawierać wyłącznie kanoniczne, indeksowalne adresy z kodem 200, a nie przekierowania, błędy ani strony z noindex. Nie zastąpi to linkowania wewnętrznego, ale porządkuje wskazówki dla Google i ogranicza liczbę niepotrzebnych odwiedzin.
Jakie praktyki pomagają w optymalizacji budżetu crawlowania?
Optymalizacja budżetu crawlowania polega na tym, aby Google częściej odwiedzał strony ważne biznesowo, a rzadziej adresy zbędne, zduplikowane lub czysto techniczne. Najwięcej sensu ma to w dużych serwisach, sklepach, portalach i witrynach z filtrami oraz parametrami. W mniejszych serwisach efekt też bywa zauważalny, ale zwykle ważniejsze pozostają podstawy: dostępność, linkowanie i jakość treści.
Pierwszym krokiem jest weryfikacja, co Google faktycznie odwiedza. Najlepiej sięgnąć po logi serwera oraz raporty crawl stats w Google Search Console, bo dopiero tam widać, czy bot zużywa czas na produkty, kategorie i artykuły, czy raczej na sortowania, wyniki wyszukiwania wewnętrznego i adresy z parametrami. Bez danych łatwo zabrać się za nie ten problem, co trzeba.
Najwięcej budżetu pochłaniają zazwyczaj duplikaty i warianty adresów. Dotyczy to filtrów, sortowania, paginacji bez kontroli, parametrów śledzących, wersji testowych oraz stron generowanych masowo bez realnej wartości. W praktyce trzeba zmniejszyć liczbę takich URL-i dzięki lepszej architekturze, poprawnym canonicalom, sensownemu linkowaniu i niewystawianiu zbędnych wariantów do indeksacji.
Drugim obszarem są usterki techniczne, które spowalniają albo wręcz przerywają crawl. Częste 5xx, timeouty, pętle przekierowań, rozbudowane łańcuchy przekierowań oraz soft 404 obniżają wydajność pobierania, bo Google musi wykonywać dodatkowe żądania lub wpada w ślepe zaułki. Im stabilniej odpowiada serwer i im krótsza droga do treści, tym sprawniej Google wraca do ważnych stron.
Duże znaczenie ma także linkowanie wewnętrzne. Podstrony istotne dla ruchu i sprzedaży powinny mieć linki z miejsc o wysokiej widoczności, a ich głębokość kliknięć powinna być możliwie najmniejsza. Jeśli kluczowa podstrona występuje wyłącznie w sitemapie albo jest ukryta kilka poziomów niżej, Google zwykle uzna ją za mniej ważną.
Warto regularnie przeglądać szablony stron, zamiast skupiać się wyłącznie na pojedynczych URL-ach. Jeden błędny wzorzec filtrowania, paginacji albo generowania parametrów potrafi wygenerować tysiące zbędnych adresów. Najlepsze efekty przynosi usunięcie przyczyny w szablonie lub logice serwisu, a nie ręczne porządkowanie pojedynczych podstron.
Jakie narzędzia są niezbędne do analizy i optymalizacji procesu crawlingu?
Do analizy i optymalizacji procesu crawlingu potrzebujesz przede wszystkim Google Search Console, logów serwera, crawlera desktopowego lub chmurowego, weryfikacji sitemap XML oraz testów renderowania. Każde z tych źródeł obejmuje inny fragment układanki: odkrywanie URL-i, realne wejścia Googlebota, błędy techniczne oraz to, co bot rzeczywiście widzi po wyrenderowaniu strony. Najczęstszy błąd polega na tym, że diagnozę opiera się wyłącznie na Search Console, bez wglądu w logi i strukturę linków wewnętrznych.
Google Search Console zapewnia najszybszy punkt wyjścia. Raport indeksowania, statystyki crawlowania, inspekcja adresu URL oraz raport sitemap pokazują, czy Google zna dany adres, kiedy go odwiedza, jaki zwraca status i czy pojawiają się problemy z pobraniem lub wyborem kanonicznej wersji. Narzędzie nie daje jednak pełnego obrazu, ponieważ nie zastępuje danych z serwera.
Logi serwera są niezbędne, gdy chcesz sprawdzić, co Google robi w praktyce, a nie co teoretycznie powinien robić. Dzięki nim zweryfikujesz, które sekcje bot odwiedza najczęściej, ile czasu traci na parametry, filtry i błędne adresy oraz czy ważne strony są pobierane regularnie. Jeśli ważne URL-e nie pojawiają się w logach albo są odwiedzane rzadziej niż mało istotne strony, problem dotyczy priorytetów crawlowania lub odkrywania adresów.
Własny crawler pozwala przejść witrynę tak, jak zrobiłby to bot, ale z perspektywy audytu technicznego. W praktyce pomaga wykrywać strony osierocone, błędne przekierowania, konflikty w canonicalach, noindexy, pętle, nadmierną głębokość kliknięć oraz problemy z linkowaniem wewnętrznym. To właśnie tu najłatwiej namierzyć miejsca, w których architektura serwisu utrudnia odkrywanie kluczowych stron.
Sitemapę XML lepiej traktować jak listę kontrolną niż potwierdzenie, że wszystko jest w porządku. Dobrze ułożona mapa powinna zawierać wyłącznie URL-e kanoniczne, indeksowalne i zwracające kod 200. Gdy w sitemapie pojawiają się przekierowania, błędy, duplikaty albo strony z noindex, wysyłasz Google niespójny komunikat i osłabiasz efektywność całego procesu.
Testy renderowania są niezbędne, gdy serwis w dużej mierze opiera się na JavaScript. Warto upewnić się, że główna treść, linki do podstron oraz elementy nawigacji są dostępne w HTML albo pojawiają się bez dodatkowych działań użytkownika. Jeżeli linki stają się widoczne dopiero po kliknięciu, rozwinięciu filtra czy doładowaniu danych z opóźnieniem, Google może dotrzeć do nich później albo w ogóle.
W praktyce najlepiej sprawdza się prosty schemat: najpierw analizujesz Search Console, później potwierdzasz obraz w logach, następnie przepuszczasz serwis przez crawlera, a na końcu weryfikujesz renderowanie kluczowych szablonów. Taka sekwencja pomaga rozdzielić problemy z indeksacją od kłopotów z odkrywaniem, pobieraniem i interpretacją strony. Nie istnieje jedno, uniwersalne narzędzie do crawlingu; trafne decyzje pojawiają się dopiero po zestawieniu kilku źródeł danych.

Jakie są najczęstsze błędy i ograniczenia w crawlowaniu i jak ich unikać?
Najczęstsze błędy i ograniczenia w crawlowaniu obejmują trudności z odkrywaniem ważnych URL-i, blokady techniczne, przepalanie budżetu na duplikaty oraz problemy z renderowaniem treści i linków. W efekcie Google albo nie dociera do kluczowych stron, albo trafia na nie zbyt późno, albo zużywa zasoby na adresy, które nie wnoszą wartości do indeksu. Zazwyczaj nie jest to jeden spektakularny błąd, lecz suma drobnych decyzji technicznych, które łącznie obniżają skuteczność.
Jednym z najczęstszych kłopotów są strony osierocone oraz słabe linkowanie wewnętrzne. Jeżeli ważna podstrona występuje wyłącznie w sitemapie albo prowadzi do niej długa ścieżka kliknięć, Google uznaje ją za mniej istotną i może odwiedzać ją rzadziej. Pomaga skrócenie ścieżek dojścia, dodawanie linków z mocnych sekcji serwisu oraz dopilnowanie, by kluczowe strony były dostępne z typowej nawigacji.
Drugą dużą kategorią problemów są duplikaty URL-i. Parametry, sortowania, filtrowanie, różne wersje tej samej kategorii, paginacja bez kontroli oraz mieszanie wariantów adresów sprawiają, że bot odwiedza liczne, bardzo podobne strony zamiast koncentrować się na właściwych. Im więcej technicznych wariantów tej samej treści, tym większe ryzyko, że Google będzie crawlować nie to, co jest biznesowo ważne.
Częstym ograniczeniem bywają również nieprawidłowe odpowiedzi serwera i błędna obsługa przekierowań. Kody 5xx, timeouty, pętle, długie łańcuchy przekierowań oraz soft 404 spowalniają pobieranie i utrudniają ocenę jakości strony. W takiej sytuacji warto uprościć ścieżki przekierowań, naprawić niestabilne szablony i dopilnować, aby każda strona docelowa zwracała jednoznaczny, poprawny status HTTP.
Osobnym wyzwaniem są sprzeczne sygnały indeksacyjne. Zdarza się, że strona jest wewnętrznie wskazywana jako istotna, a jednocześnie ma noindex, błędnie ustawiony canonical albo zostaje zablokowana przed pobraniem zasobów potrzebnych do renderowania. Dla Google nie jest to drobna rozbieżność, lecz wyraźny znak, że nie wiadomo, którą wersję uznać za właściwą.
W serwisach opartych na JavaScript barierą bywa sama architektura interfejsu. Jeżeli treść pojawia się dopiero po wykonaniu skryptów, a linki są ukryte w komponentach wymagających interakcji, odkrywanie adresów trwa dłużej i robi się mniej przewidywalne. Jeśli kluczowy tekst i linki nie są dostępne od razu w kodzie HTML, warto uprościć renderowanie albo zapewnić wersję, którą Google odczyta bez dodatkowych kroków.
Aby ograniczać te błędy, należy regularnie zestawiać cztery elementy: co znajduje się w sitemapie, co wynika z linkowania wewnętrznego, co odwiedza Google w logach oraz co ostatecznie trafia do indeksu. Kiedy te cztery obrazy się rozjeżdżają, źródło problemu zwykle da się szybko namierzyć. Najskuteczniejsza optymalizacja crawlingu nie polega na „przyspieszaniu Google”, tylko na usuwaniu przeszkód, przez które bot traci czas.


