

Analiza logów to dokładny sposób analizowania tego jak wyszukiwarki odczytują nasze strony. Każdego dnia specjaliści SEO i analitycy wykorzystują narzędzia przedstawiające diagramy ruchu, zachowania użytkowników i konwersji. Co więcej, specjaliści zwykle starają się zrozumieć, jak Google analizuje ich strony za pomocą Google Search Console. Warto zwrócić uwagę na podstawy związane z narzędziami do logów serwerowych. Za pomocą których sprawdza się czy wyszukiwarka prawidłowo radzi sobie ze stroną – choćby za sprawą kodów statusu odpowiedzi (404, 503, 302), i tak dalej!
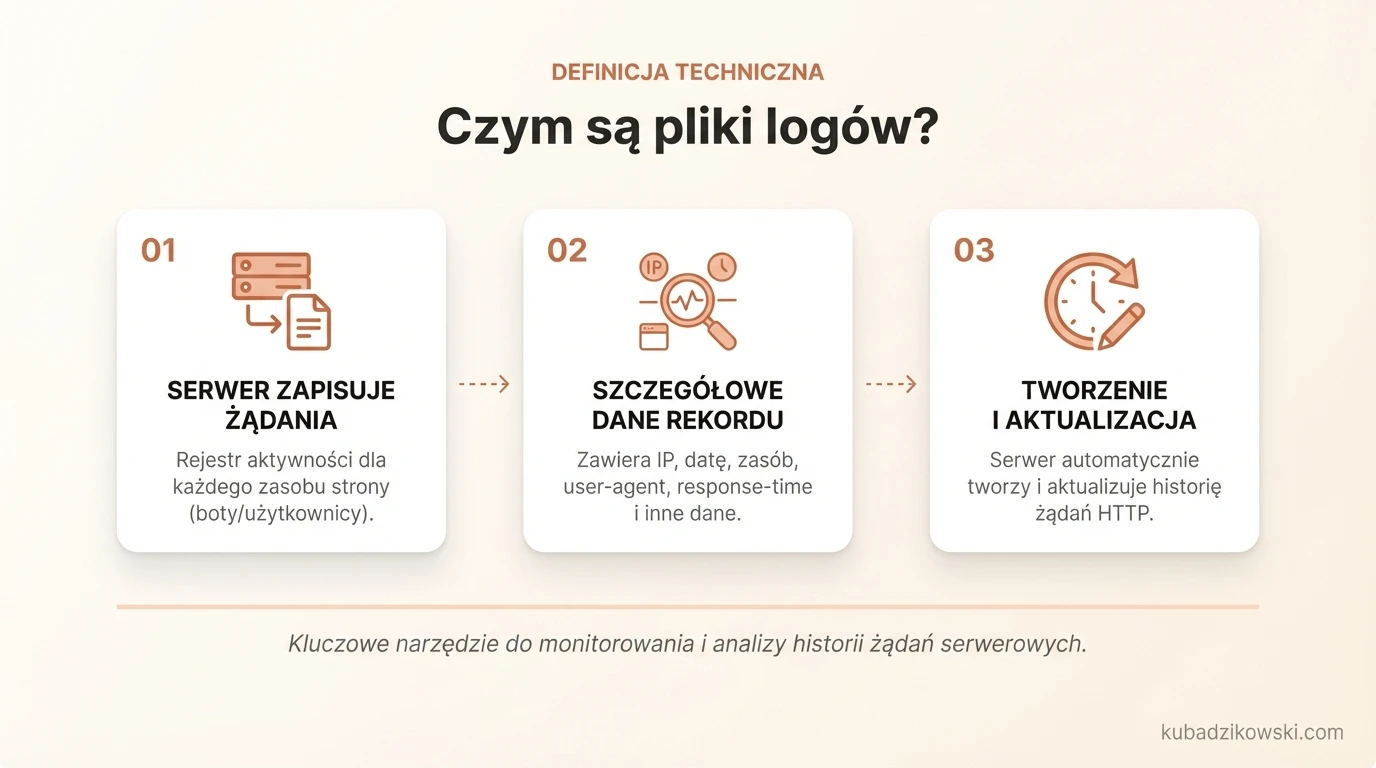
Czym są pliki logów?
Plik logu jest plikiem, w którym serwer sieciowy zapisuje wers dla każdego pojedynczego zasobu strony internetowej, który jest wymagany przez boty lub użytkowników. Każdy wers zawiera dane na temat żądania, które mogą obejmować IP, datę, wymagany zasób (strona, .css, .js, …), user-agent, response-time, …
Fragment może wyglądać na przykład następująco:
66.249.**.** – – [13/Apr/2021:00:07:31 +0200] “GET /***/x_*** HTTP/1.1” 200 40960 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)” “www.***.it” “-“
Logi serwerowe są tworzone i aktualizowane przez serwer, który rejestruje wykonane czynności. Popularnym plikiem logów serwera jest plik dostępu, który zawiera historię żądań HTTP przekazywanych do serwera (zarówno przez użytkowników, jak również boty).
W przypadku zażądania logów od dewelopera, w pierwszej kolejności zapytają oni o które logi chodzi. W związku z tym zawsze trzeba precyzyjnie określić swoją prośbę. Poszukując logów do analizy crawlingu, należy zapytać o logi dostępu.
Pliki logów dostępu zawierają wiele informacji na temat każdej prośby przekazanej do serwera, takich jak na przykład:
- adresy IP,
- user agents,
- URL,
- Timestamps (kiedy bot/wyszukiwarka przekazała żądanie),
- typ żądania (GET lub POST),
- kody statusu HTTP.

To co serwery umieszczają w logach dostępowych różni się w zależności od typu serwera, a czasami od tego jak deweloperzy skonfigurowali serwer pod kątem elementów przechowywanych w plikach logów. Popularne formaty plików logów obejmują między innymi następujące rodzaje:
- Format Apache – jest on wykorzystywany przez serwery Nginx oraz Apache.
- Format W3C – jest on wykorzystywany przez serwery Microsoft IIS.
- Format ELB – jest on wykorzystywany przez Amazon Elastic Load Balancing.
- Formaty niestandardowe – wiele serwerów wspiera przesyłanie niestandardowych formatów logów.
Istnieją też inne formaty, ale powyżej przedstawione są te, które można napotkać najczęściej.

Możliwość analizowania i aktualizacji
Każda strona posiada trzy podstawowe statusy SEO:
- możliwa do analizowania (crawlable),
- możliwa do zindeksowania (indexable),
- możliwa do umieszczenia w rankingu (rankable).
Z perspektywy analizy logów, można dowiedzieć się, że strona, aby została zindeksowana, musi zostać przeczytana przez bota. Podobnie treść, która już została zindeksowana przez wyszukiwarkę, musi zostać ponownie przeanalizowana, aby została zaktualizowana w indeksach wyszukiwarki.
Niestety w Google Search Console nie ma takiego poziomu szczegółowości. Można sprawdzić, ile razy Googlebot czytał podstronę danej strony w ostatnich trzech miesiącach. Możliwe jest też sprawdzenie, jak szybko odpowiadał serwer sieciowy.
Można jednak sprawdzić, czy bot przeczytał stronę. Jest to możliwe dzięki wykorzystaniu plików logu w analizatorze logów.

Dlaczego specjaliści z branży SEO muszą analizować pliki logów?
Analiza plików logów pozwala specjalistom SEO (oraz administratorom systemów) zrozumieć:
- co dokładnie czyta bot,
- jak często bot to czyta,
- jaki jest czas spędzony na crawlingu (ms).
Narzędzie do analizy logów umożliwia ich analizowanie poprzez grupowanie informacji pod względem „ścieżki”, rodzaju plików lub czasu odpowiedzi. Porządne narzędzie do analizy logów pozwala na przyłączanie informacji pozyskanych z plików logów z informacjami z innych źródeł danych, takich jak Google Search Console (kliknięcia, wyświetlenia, średnie pozycje) lub Google Analytics.

Czego należy szukać w plikach logów?
Pierwszym etapem w zrozumieniu tego dlaczego strona nie została zindeksowana lub zaktualizowana do najnowszej wersji jest sprawdzenie czy bot (np. Googlebot) ją crawlował.
Następnie, jeśli strona jest często aktualizowana, ważne może być to, aby sprawdzić jak często bot czyta stronę lub jej sekcję.
Kolejnym krokiem jest sprawdzenie, które podstrony są najczęściej czytane przez boty. Śledząc je można sprawdzić czy takie strony:
- zasługują na takie częste czytanie,
- są skanowane tak często, ponieważ coś na stronie powoduje stałe zmiany wykraczające poza kontrolę.
Przykładowo, problemem była strona, która odnotowywała wysoką częstotliwość skanowania przez boty pod dziwnym adresem URL. Bot wykazał, że strona ta pochodzi z URL stworzonego przez JavaScript i została ona oznaczona pewnymi wartościami debugowania, które zmieniały się przy każdym ładowaniu strony. Na podstawie takich informacji, dobry specjalista SEO z pewnością znajdzie właściwe rozwiązanie problemu takiej dziury w crawl budget.
Crawl Budget
Każda strona posiada metaforyczny budżet indeksowania (crawl budget) powiązany z wyszukiwarkami i ich botami. Nie jest on nigdzie rejestrowany, ale można go oszacować na dwa sposoby:
- sprawdzanie raportu ze statystykami crawlingu w Google Search Console,
- sprawdzanie plików logów, oraz ich filtrowanie pod kątem użytkownika zawierającego w nazwie „Googlebot” (Najlepsze rezultaty można uzyskać upewniając się, że tacy użytkownicy są dopasowani do prawidłowych numerów IP Google…).
Crawl Budget zwiększa się, gdy strona jest aktualizowana i trafia na nią interesująca treść, a także gdy jej treść jest regularnie aktualizowana lub gdy strona pozyskuje dobre linki zwrotne.
Sposobem wykorzystywania crawl budget na stronie można zarządzać poprzez:
- linki wewnętrzne (w tym również follow / nofollow),
- noindex / canonical,
- robots.txt (uwaga: powoduje to blokadę user-agent).
Strony „zombie”
Pod pojęciem stron „zombie” można rozumieć wszystkie strony, które nie odnotowały jakiegokolwiek ruchu organicznego czy też wizyt botów przez znaczny okres czasu, ale posiadają linki wewnętrzne, które do nich kierują.
Taki typ strony może zużyć zbyt wiele crawl budget oraz może otrzymać niepotrzebny Page Rank ze względu na linki wewnętrzne. Taką sytuację można rozwiązać w następujący sposób:
- Jeśli te podstrony są przydatne dla użytkowników odwiedzających stronę, można je ustawić jako noindex oraz ustanowić prowadzące do nich linki wewnętrzne jako nofollow (lub wykorzystać disallow robots.txt, ale należy w tym przypadku zachować ostrożność…),
- Jeśli te strony nie są przydatne dla użytkowników odwiedzających stronę, wówczas można je usunąć (i ustawić zwrotny kod statusu 410 lub przekierować 301, a także usunąć wszystkie linki wewnętrzne.


