

Wyobraźmy sobie sytuację, w której ktoś każe przeanalizować cały Internet i stworzyć listę wszystkich zawartych w nim stron w ciągu jednego dnia. Z pewnością każdy odpowie, że jest to niemożliwe do zrobienia przez człowieka.
Na szczęście wyszukiwarki internetowe rozumieją ten problem i dlatego wysyłają specjalne roboty, które wykonują takie zadania. Boty analizują stronę razem z miliardami innych serwisów, aby uzyskać informacje na ich temat.
Czym jest crawling w SEO?
Mówiąc najprościej, jak to tylko możliwe, z crawlingiem mamy do czynienia, gdy wyszukiwarki wysyłają robota na stronę internetową lub wpis, aby go przeczytać. Jest to proces polegający na wysyłaniu robotów po to, aby znajdowały nową lub zaktualizowaną treść.
Crawling, czyli tak zwane pełzanie po sieci, polega na otwieraniu kolejnych linków i zapoznawaniu się z ich zawartością. Celem wyszukiwarek internetowych jest szybki i skuteczny crawling Internetu. Trzeba jednak pamiętać, że jest to duże wyzwanie ze względu na ogromną ilość stron w sieci.
W 2008 roku Google przeanalizowało 1 bilion stron. W 2013 było to już 30 bilionów stron, a w 2017 roku udało się osiągnąć 130 bilionów. Można więc zdać sobie sprawę, że odkrycie konkretnej strony przez Google to nie lada wyczyn.
Dlatego zrozumienie jak wyszukiwarki analizują strony to jedyny sposób, aby sprawić by zauważyły daną stronę.
Crawling to jedna z podstawowych funkcji wyszukiwarek. Pozostałe dwie to indeksowanie i tworzenie rankingu.
Indeksowanie to przechowywanie i organizacja treści wykrytej podczas crawlingu. Gdy strona zostanie zaindeksowana, będzie wyświetlana jako rezultat wyszukiwania dla odpowiednich zapytań.
Ranking zapewnia treść, która najlepiej odpowiada na zapytania użytkowników. Najbardziej odpowiednie będą znajdować się na górze listy, a najmniej odpowiednie na jej dole.

Różne typy robotów wyszukiwarek
Roboty wyszukiwarek to programy komputerowe, które odwiedzają serwisy internetowe i czytają ich strony, aby dokonywać wpisów w indeksie wyszukiwarki.
Poniżej znajdują się niektóre najpopularniejsze roboty:
- GoogleBot,
- BingBot,
- Sogou Spider,
- Facebook external Hit,
- SlurpBot,
- DuckDuckBot,
- AppleBot.
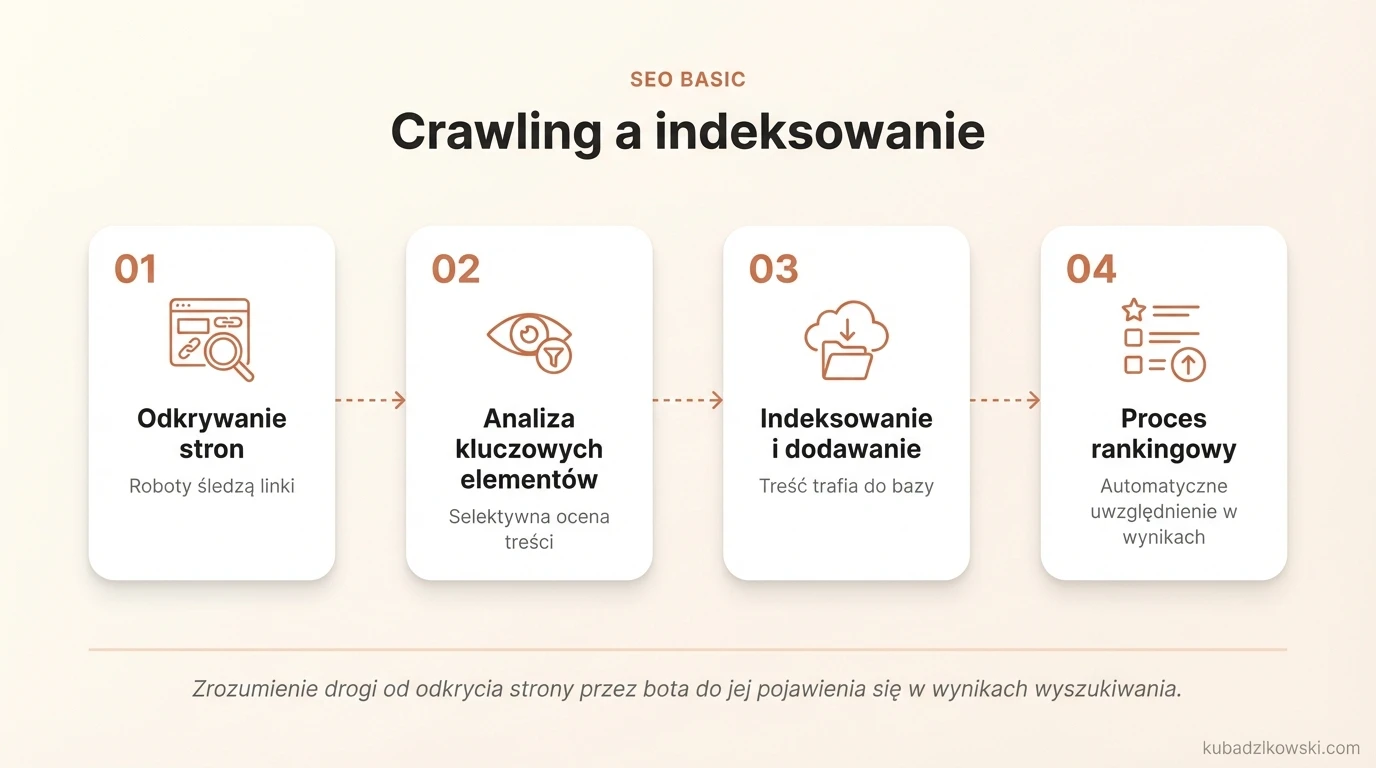
Crawling a indeksowanie
Wiele osób zastanawia się jak Google lub jakakolwiek inna wyszukiwarka decyduje, którą stronę należy przeanalizować.
Odpowiedź jest prosta: istnieją programy komputerowe, które określają jakie strony analizować i jak wiele stron wyciągnąć z serwisu oraz jak często roboty mają analizować stronę.
Robot rozpoczyna swoją pracę od listy adresów internetowych i wykorzystuje linki znajdujące się na tych stronach, aby odkrywać inne strony. Zwraca on szczególną uwagę na:
- nowe strony,
- zmiany dokonane w istniejących stronach,
- niedziałające linki.
Indeksowanie rozpoczyna się po crawlingu. Jest to moment, w którym rozpoczyna się proces rankingowy po przeanalizowaniu strony przez robota. Indeksowanie to nic innego jak dodawanie treści strony internetowej do wyszukiwarki tak, aby była ona uwzględniana w rankingu.
Nie trzeba robić niczego, aby strona została zindeksowana. Zajmują się tym roboty Google. Analizują one stronę i zapisują kopię informacji na serwerze indeksu. Gdy użytkownik użyje odpowiedniego zapytania, wyszukiwarka pokaże mu stronę.
W związku z tym, bez crawlingu, strona nie zostanie zindeksowana. Skutkiem tego nie pojawi się ona w rezultatach wyszukiwania.
Crawl budget – co to takiego?
Wyobraź sobie, że jesteś robotem wyszukiwarki i odpowiadasz za analizowanie wszystkich stron w Internecie. Jak przeprowadzałbyś crawling? (Wybierz jedną z opcji podanych poniżej)
- opcja A: będziesz analizować każdą stronę składową strony internetowej przed crawlingiem kolejnej strony, ale nie będziesz w stanie przeanalizować każdej strony w Internecie,
- opcja B: przeznaczysz ustalony czas na crawling strony internetowej przed przejściem do kolejnej, w ten sposób umożliwiając sobie analizę wszystkich stron, ale nie będziesz w stanie przeanalizować każdej strony kompletnie.
Można zauważyć, że opcja B prezentuje się lepiej.
Google przeprowadza crawling w taki sam sposób. Posiada tak zwany crawl budget, więc wykonuje swoje działania przestrzegając tego budżetu.
Mówiąc prościej, ilość czasu i zasobów wykorzystywanych przez Google podczas analizowania strony nazywa się ogólnie budżetem crawlingu (Crawl budget).
To oznacza, że po wyczerpaniu budżetu crawlingu, robot przestanie odwiedzać stronę i przejdzie do kolejnej.
Budżet crawlingu danej strony zależy od poniższych czynników:
- popularność strony w Internecie,
- możliwości serwera,
- świeżość treści,
- wielkość strony wpływa na budżet crawlingu (im jest ona większa, tym większy jest budżet).
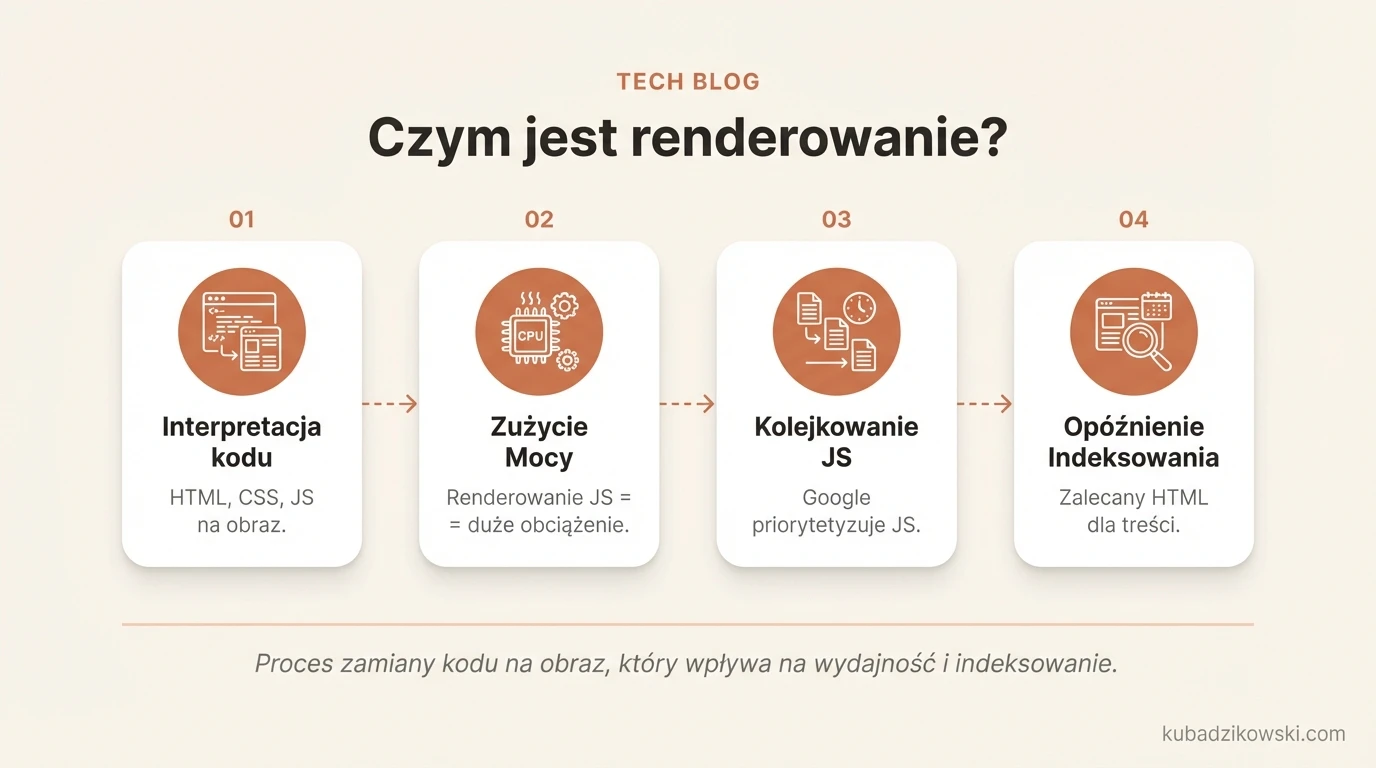
Czym jest renderowanie?
Renderowanie to interpretowanie HTML, CSS oraz JavaScript na stronie w celu stworzenia wizualnego obrazu tego co jest widoczne w przeglądarce. Przeglądarka renderuje kod na stronie internetowej.
Renderowanie kodu HTML wykorzystuje moc przetwarzania komputera. Jeśli strony działają na bazie JavaScript renderującego treść strony, przetwarzanie jest ogromne.
Google potrafi analizować i renderować strony JavaScript. Renderowanie JS trafia do kolejki pod względem priorytetów. W zależności od istotności strony, dotarcie do niej może zająć trochę czasu. W przypadku posiadania bardzo dużej strony wymagającej renderowania treści przez JavaScript, indeksowanie nowych lub zaktualizowanych stron może trochę potrwać. Zaleca się więc dostarczanie, w miarę możliwości, treści i linków w HTML, a nie JavaScript.

Segmentacja strony
Segmentacja strony lub analiza poziomu bloku pozwala wyszukiwarce na zrozumienie różnych elementów strony: nawigacji, reklam, treści, stopki, itp. Algorytm może tutaj zidentyfikować, która część strony zawiera najważniejsze informacje lub podstawową treść. Pozwala to wyszukiwarce zrozumieć o czym jest dana strona i uniknąć zmylenia przez inne elementy.
Google wykorzystuje takie rozumowanie do degradacji niskiej jakości doświadczeń, takich jak na przykład zbyt wiele reklam na stronie lub zbyt mało treści w górnej części.
Dokument badawczy opublikowany przez Microsoft wyjaśnia jak różne sekcje strony mogą być rozumiane przez algorytm.Segmentacja strony przydaje się również do analizy linków.
Tradycyjnie różne linki na stronie są traktowane identycznie. Podstawowe założenie analizy linków mówi o tym, że jeśli istnieje link pomiędzy dwiema stronami, wówczas istnieje pomiędzy nimi pewne powiązanie w całości. Jednak w większości przypadków link prowadzący ze strony A do strony B tylko wskazuje, że może istnieć jedynie powiązanie pomiędzy pewną określoną częścią strony A i określoną częścią strony B.
Taki typ analizy pozwala linkom kontekstowym znajdującym się w większych blokach treści na uzyskanie większej mocy (wartości) niż linki pojawiające się w menu nawigacji, stopce lub na pasku bocznym. Znaczenie linku może zostać ocenione na podstawie tego co znajduje się przy nim oraz gdzie został on znaleziony na stronie.
Google wykorzystuje również patenty segmentacji strony, zwracając uwagę na widoczne luki lub białe przestrzenie na renderowanej stronie.
Czy można wskazać wyszukiwarkom jak mają analizować stronę?
Tak, można definitywnie wskazać wyszukiwarkom jak mają analizować stronę. Dzięki temu można lepiej kontrolować to co zostanie zindeksowane. Można odciągnąć Googlebota od pewnych stron, które nie mają zostać zindeksowane.
Chodzi tutaj głównie o adresy URL z powieloną treścią, małą ilością treści, strony testowe lub strony ze specjalnymi kodami promocyjnymi.
Aby zapobiec analizowaniu określonych stron przez Googlebota, należy skorzystać z pliku robots.txt.
Czego wyszukiwarki nie widzą?
Trudna nawigacja
Wiele stron posiada nawigację, która jest niedostępna dla wyszukiwarek. To z kolei pogarsza ich możliwość pojawienia się w indeksie i w rezultatach wyszukiwania.
- jeśli elementy menu nie są w HTML, wyszukiwarka może mieć problem z ich odczytaniem,
- może być to spowodowane posiadaniem dwóch typów nawigacji dla różnych urządzeń, takich jak komputery i urządzenia mobilne,
- brak linkowania do podstawowej strony z nawigacji może również utrudnić jej znalezienie przez wyszukiwarkę.
Zabezpieczone strony
Jeśli na określonych stronach użytkownicy muszą się logować, odpowiadać na pytania w ankietach lub wypełniać formularze, wówczas roboty nie zobaczą tych zabezpieczonych stron.
Treść ukryta w elementach, które nie są tekstem
Należy unikać wykorzystywania form nietekstowych, aby pokazać tekst, który ma zostać zindeksowany. Wyszukiwarki mogą bowiem nie odczytać takiej treści. Najlepiej jest napisać tekst w znaczniku na stronie.
Jak informować roboty o tym co mają analizować?
Istnieje wiele sposobów poinformowania robotów o tym co mają analizować. Niektóre metody zostały przedstawione poniżej.
Wykorzystanie mapy strony
Sitemapa strony informuje Google o tym, które strony są istotne. Może również kierować roboty pod względem częstotliwości ponownego crawlingu. Oczywiście Google może znaleźć strony bez ich uwzględniania w mapie strony, ale warto jest im to ułatwić.
Aby sprawdzić czy strona znajduje się na mapie strony, należy przejść do Search Console i użyć narzędzia inspekcji linków URL. Można również zrobić to samo przechodząc pod adres URL swojej sitemapy (twojadomena.com/sitemap.xml) i szukając strony.
Plik Robots.txt
Pliki te znajdują się w katalogu głównym strony.
Katalog ten (https://twojadomena.com/robots.txt) jest miejscem, w którym można znaleźć plik robots.txt. Następnie można w tym pliku zasugerować strony Twojego serwisu, które mają być analizowane.
Robot sprawdzi plik robots.txt i przejdzie do crawlingu strony uwzględniając sugestie.
Poszukiwanie „osieroconych stron”
Osierocone strony to takie, które nie posiadają linków wewnętrznych prowadzących z innych stron. Google analizuje i odkrywa nową treść, ale roboty nie są w stanie odkrywać takich stron. Aby sprawdzić czy serwis zawiera osierocone strony, można wykorzystać narzędzie Ahref’s Site Audit.
Linki wewnętrzne z tagiem nofollow
Google nie analizuje linków „nofollow”, więc należy upewnić się, że linki wewnętrzne stron przeznaczonych do indeksowania nie zawierają tagu „nofollow”.
Graf wiedzy (Knowledge graph)
Google wykorzystało swoją ogromną bazę informacji, aby stworzyć graf wiedzy. Wykorzystuje on znalezione dane, aby rozplanować entities (podmioty) lub przedmioty. Fakty są łączone z rzeczami, a pomiędzy rzeczami tworzone są powiązania. Przykładowo film posiada bohaterów powiązanych z książką napisaną przez autora, którego rodzina posiada inne powiązania, itp.
W 2012 roku firma Google poinformowała, że uwzględnia ponad 500 milionów przedmiotów oraz ponad 3,5 miliarda faktów na temat powiązań pomiędzy przedmiotami i podmiotami. Fakty zebrane i wyświetlane dla każdego entity są napędzane typami wyszukań widzianych przez Google dla różnych rzeczy.
Graf wiedzy może również wyjaśnić ewentualne nieporozumienia i niejasności pomiędzy rzeczami o tej samej nazwie. Przykładowo hasło „Taj Mahal” może dotyczyć poszukiwania informacji o architektonicznym cudzie świata lub może być związane z najnowszym kasyno Taj Mahal albo z lokalną restauracją hinduską.
Wyszukiwanie konwersacyjne
Dawniej, przy uruchomieniu Google, wyszukiwarka zwracała rezultaty, które zawsze zawierały wyszukiwane słowa. Rezultaty wyszukiwania były po prostu nakierowane na dopasowanie wyszukiwanych słów kluczowych do takich samych słów kluczowych znalezionych w dokumentach w Internecie.
Znaczenie zapytania nie było rozumiane, więc Google miało problem z wyszukiwaniem w formie pytań. Po latach uległo to jednak zmianie.
Google zainwestowało w algorytmy przetwarzania języka naturalnego, aby zrozumieć jak słowa wpływały na siebie oraz co dane zapytanie oznacza.
W 2012 roku Google wprowadziło możliwość „wyszukiwania konwersacyjnego” zapewnianą przez Graf wiedzy. W 2013 roku uruchomiono algorytm Hummingbird, który stanowił główne udoskonalenie pozwalające Google na przetwarzanie semantyki lub znaczenia każdego słowa w każdym zapytaniu.
Znaczenie crawlingu i indeksowania dla strony
To od tych działań rozpoczyna się optymalizacja pod kątem wyszukiwarek. Jeśli Google nie jest w stanie przeanalizować Twojej strony, nie zostanie ona uwzględniona w żadnych rezultatach wyszukiwania. Należy też sprawdzać plik robots.txt. Kontrola techniczna SEO strony powinna wykazać wszelkie inne problemy z dostępnością dla robotów wyszukiwarek.
Jeśli strona jest przeciążona, zawiera błędy lub strony niskiej jakości, Google może odnieść wrażenie, że serwis składa się głównie z bezużytecznych stron. Błędy kodowania, ustawień CMS lub strony zaatakowane przez hakerów informują Googlebota o stronach niskiej jakości. Jeśli stron niskiej jakości jest więcej niż stron wysokiej jakości, wówczas ucierpi na tym pozycja serwisu w rankingu wyszukiwania.
Jak sprawdzać problemy z crawlingiem i indeksowaniem?
Wyszukiwanie Google
Można sprawdzić jak Google indeksuje stronę, przy pomocy komendy „site:”. Należy ją wpisać w polu wyszukiwania Google, aby zobaczyć wszystkie strony danego serwisu, które zostały zaindeksowane. Operatory Google-a są niezwykle przydatne, ale nie należy ich brać za 100 procentową wyrocznię, bo idealnie nie działają.
site:twojadomena.com
Możesz sprawdzić wszystkie strony dzielące ten sam katalog (lub ścieżkę) w serwisie, jeśli zostanie to uwzględnione w zapytaniu.
site:twojadomena.com/blog/
Można wykorzystać „site:” wraz z „inurl:” oraz znaku minus, aby usunąć dopasowania i uzyskać bardziej szczegółowe rezultaty.
site:twojadomena.com -site:support.twojadomena.com inurl:2019
Należy sprawdzić czy tytuły i opisy zostały zaindeksowane w sposób zapewniający najlepsze doświadczenia. Warto upewnić się, że nie zostały zaindeksowane żadne niespodziewane i dziwne oraz inne niepotrzebne strony.
Google Search Console
Posiadając stronę internetową, należy zweryfikować ją w Google Search Console. Dane zawarte w tym narzędziu są bezcenne.
Google dostarcza raporty dotyczące skuteczności w zakresie rankingu wyszukiwania: wyświetlenia i kliknięcia pod względem stron, krajów lub typów urządzeń do 16 miesięcy wstecz. W raportach Index Coverage można znaleźć wszelkiego typu błędy znalezione przez Google. Istnieją też inne przydatne raporty związane z ustrukturyzowanymi danymi, prędkością strony oraz sposobem indeksowania strony przez Google.
Raport Crawl Stats można znaleźć w Legacy Reports (na ten moment). Dzięki temu można sprawdzić jak Google analizowało stronę (szybko lub wolno, wiele lub mniej stron, itp.).

Wykorzystanie robota wyszukiwarki
Warto spróbować użyć robota wyszukiwarki, aby lepiej dowiedzieć się jak wyszukiwarka analizuje stronę. Istnieje wiele opcji dostępnych za darmo. Jedną z najpopularniejszych jest Screaming Frog, która zawiera doskonały interfejs, mnóstwo funkcji oraz pozwala na crawling do 500 stron za darmo.

Sitebulb to kolejna doskonała opcja, jeśli chodzi o robota z wieloma funkcjami i lepszą wizualną prezentacją danych. Xenu’s Ling Sleuth to starszy robot, ale jest całkowicie darmowy. Nie posiada on wielu funkcji pozwalających na identyfikację problemów z SEO, ale może szybko analizować duże strony internetowe i sprawdzać kody statusów oraz to jakie strony są ze sobą powiązane.
Analiza logów serwera
Jeśli chodzi o zrozumienie jak Google analizuje stronę internetową, nie ma nic lepszego od logów serwera. Serwer sieciowy można skonfigurować tak, aby zapisywał pliki logów zawierające każde żądanie lub działanie użytkownika. Pliki te obejmują ludzi odwiedzających strony poprzez ich przeglądarki oraz wszelkie roboty, takie jak Googlebot.
Nie uzyskasz informacji na temat tego jakie są doświadczenia robotów wyszukiwarek odnośnie danej strony z aplikacji Web Analytics, takich jak Google Analytics. Jest to spowodowane tym, że roboty wyszukiwarek nie wykorzystują tagów analitycznych JavaScript lub są one filtrowane.
Analizowanie tego jakie strony są sprawdzane przez Google jest bardzo przydatne. Pozwala to zrozumieć czy roboty analizują najważniejsze strony. Pomocne jest pogrupowanie stron pod względem typów, aby sprawdzić ile budżetu crawlingu jest przeznaczonego na dany tym strony. Można również grupować strony blogowe, strony „o nas”, strony tematyczne, autorskie i strony wyszukiwania. Jeśli zauważysz duże zmiany w typach analizowanych stron lub duże natężenie crawlingu dla pojedynczego typu strony (na niekorzyść innych), może to wskazywać na problem z crawlingiem, który należy sprawdzić.

Możliwość crawlingu całego Internetu i szybkiego odnajdywania aktualizacji to niesamowite osiągnięcie inżynierii. Sposób w jaki Google rozumie treść stron, powiązania (linki) pomiędzy stronami oraz znaczenie słów, może wydawać się magiczny, ale wszystko jest oparte o przetwarzanie języka naturalnego i lingwistykę komputerową. Może i nie do końca rozumiemy tych zaawansowanych rozwiązań, ale za to jesteśmy w stanie zapoznać się z ich możliwościami. Poprzez crawling i indeksowanie Internetu Google może rozpoznawać znaczenie oraz jakość na podstawie pomiarów i kontekstu.


