

Właścicielom stron internetowych zależy na tym, aby ich serwisy indeksowały się szybko. W związku z tym istotne jest zapoznanie się z pojęciem znanym jako crawl budget (budżet indeksowania). Jest ono związane zarówno z mniejszymi, jak i większymi stronami, jednak najczęściej dotyczy on większych serwisów, w których istnieje ryzyko występowania różnych błędów.
Wspomniany wyżej budżet jest ściśle powiązany z tak zwanym crawlingiem. W idealnym scenariuszu polega on na tym, że Google wysyła swoje roboty, które przeglądają strony internetowe, a następnie indeksują treści, które się na nich znajdują. Po wykonaniu takich zadań, dana treść zostanie uwzględniona w indeksie wyszukiwarki.
W związku z tym istotne jest ułatwienie Google znalezienia wszystkich istotnych stron. To dlatego kluczowe jest tworzenie sitemap ułatwiających znalezienie robotom adresów URL, a także właściwej struktury informacji strony.
W przypadku mniejszych stron posiadających do kilkuset adresów URL, crawling przebiega dość szybko. Jeśli jednak serwis obejmuje wiele tysięcy podstron, które są regularnie dodawane i aktualizowane codziennie, wówczas ważne jest ustalenie co i kiedy powinno przejść proces crawlingu.

Crawl Budget – co to takiego?
Pojęcie Crawl Budget wiąże się z dwoma podstawowymi czynnikami, jakimi są Crawl Rate oraz Crawl Demand. Warto więc dokładniej się z nimi zapoznać.

Crawl Rate Limit
Limit współczynnika crawlowania powstał po to, aby Google nie przeprowadzał crawlingu wielu podstron naszego serwisu w zbyt krótkim czasie. W ten sposób serwer danej strony nie jest przeciążony. Innymi słowy Crawl Rate Limit sprawia, że Google nie wysyła zbyt dużej liczby zapytań (requestów) sprawiających, że strona będzie działać wolniej.
Oczywiście współczynnik ten jest również uzależniony od tego jaka jest szybkość działania strony. Wolno działająca strona i serwer sprawiają, że tempo crawlingu znacznie spada, a efektem tego jest przeanalizowanie tylko kilku podstron przez Google. Zakres indeksowania znacznie wzrasta w przypadku szybszych stron.
Crawl Demand
Pod tym pojęciem kryje się zapotrzebowanie na indeksowanie. Jeśli jest ono niskie dla danej strony, wówczas robot Google nie będzie przeprowadzał na niej crawlingu. Według informacji podanych przez Google, aktualizowana na bieżąco, popularna treść posiada wyższą wartość takiego współczynnika. Zapotrzebowanie to jest też uzależnione od popularności stron oraz od tego czy zawierają aktualną i oryginalną treść.
*Na podstawie powyższych pojęć można stwierdzić, że Crawl Budget to liczba podstron albo adresów URL danej witryny, które są poddawane procesowi crawlingu przez robota Google z uwzględnieniem Crawl Demand i Crawl Rate Limit.
Jak Google ustala Crawl Budget?
Crawl Budget (budżet indeksowania) oznacza czas i zasoby wykorzystywane przez Google do analizowania danej strony internetowej. Można to przedstawić w formie następującego równania:
Crawl Budget = Crawl Rate + Crawl Demand
Autorytet domeny, linki zwrotne, prędkość działania strony, błędy crawlingu oraz liczba stron docelowych to czynniki mające wpływ na Crawl Rate (współczynnik indeksowania) strony. Większe strony zwykle posiadają większy współczynnik, natomiast mniejsze i wolniejsze strony oraz serwisy z nadmierną liczbą przekierowań i błędów serwera, zwykle są analizowane dużo rzadziej.
Google ustala również Crawl Budget na podstawie „Crawl Demand”. Popularne adresu URL posiadają wyższe zapotrzebowanie na crawling, ponieważ Google chce dostarczać użytkownikom najświeższą treść. Google nie lubi nieaktualnej treści w swoim indeksie, więc strony, które nie były analizowane przez pewien czas, również mają wyższy Crawl Demand.
Crawl Budget danej strony internetowej może się zmieniać i z pewnością nie jest stały. Polepszając hosting lub prędkość strony, można sprawić, że robot Google będzie częściej analizować stronę wiedząc, że nie będzie to spowalniało jej działania dla realnych użytkowników. Aby dowiedzieć się czegoś więcej na temat aktualnego średniego Crawl Rate dla danej strony, należy sprawdzić Crawl Report w Google Search Console.

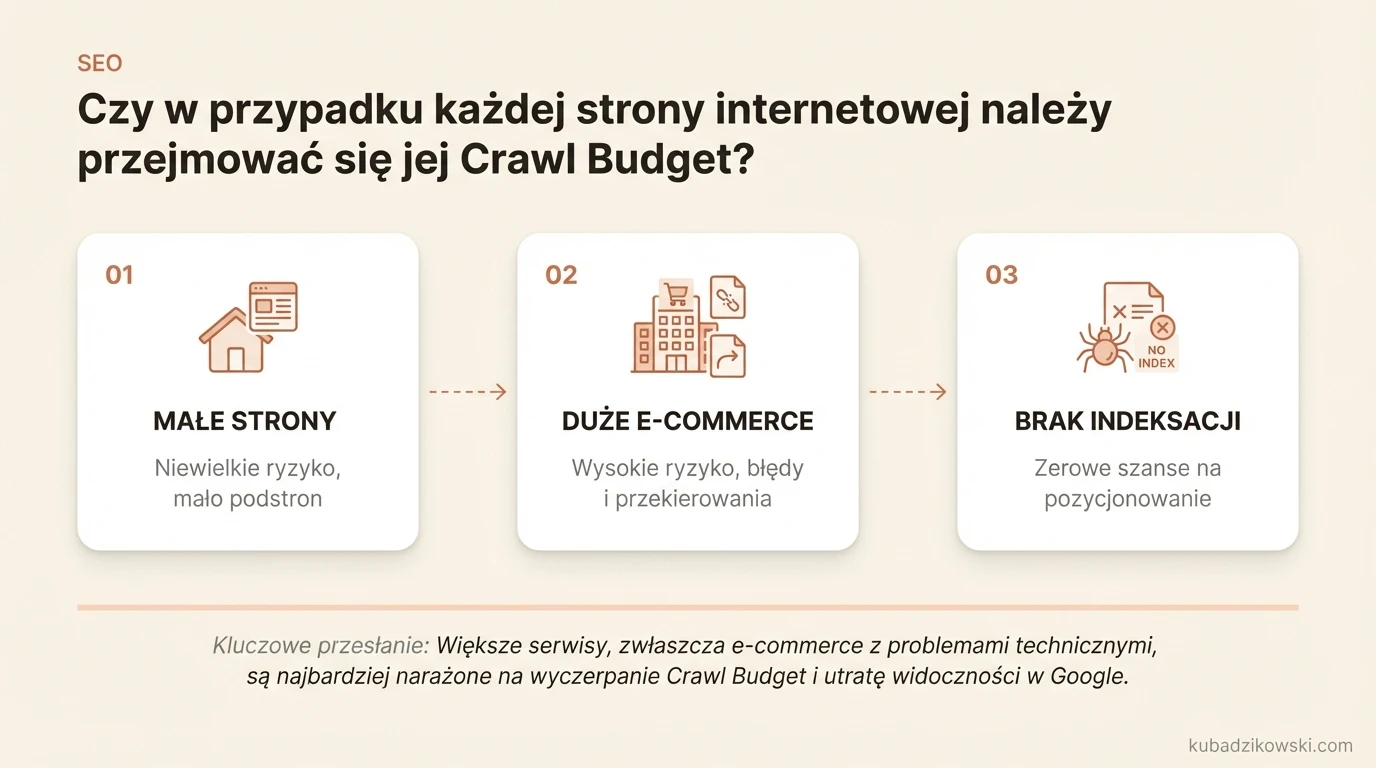
Czy w przypadku każdej strony internetowej należy przejmować się jej Crawl Budget?
Mniejsze strony internetowe, które skupiają się tylko na pozycjonowaniu niewielu podstron docelowych, nie muszą nadmiernie martwić się Crawl Budget. Jednak większe strony, w szczególności takie, które zawierają niedziałające właściwie podstrony i przekierowania, mogą dość szybko osiągnąć swój limit crawlingu.
Największe ryzyko wyczerpania Crawl Budget zwykle dotyczy stron, które posiadają dziesiątki tysięcy podstron docelowych. Duże strony internetowe e-commerce są w szczególności często narażone na negatywne oddziaływanie na Crawl Budget. Wiele stron dużych przedsiębiorstw posiada znaczącą ilość podstron docelowych, które nie zostały zindeksowane. To oznacza zerowe szanse na pozycjonowanie w Google.
Istnieje kilka powodów, dla których w szczególności strony e-commerce muszą zwracać większą uwagę na to jak jest wykorzystywany ich Crawl Budget.
- Wiele stron e-commerce jest zbudowanych z tysięcy podstron docelowych z produktami lub z miastami i regionami, w których sprzedają swoje produkty.
- Te typy stron, które regularnie aktualizują swoje podstrony docelowe, gdy kończy się towar w magazynie, dodawane są nowe produkty lub pojawiają się inne zmiany w zapasach.
- Strony e-commerce, które mają tendencję do tworzenia duplikatów podstron (np. stron z produktami) oraz identyfikatorów sesji (np. cookies). Oba te przypadki są uznawane za adresy URL “niskiej wartości” przez robota Google, a to wpływa niekorzystnie na Crawl Rate.
Kolejną kwestią, jeśli chodzi o wpływ na Crawl Budget jest to, że Google może go zwiększyć lub zmniejszyć w dowolnym czasie. Pomimo, że sitemap (mapa strony) jest istotna w przypadku dużych stron w celu usprawnienia crawlingu i indeksowania ich najważniejszych stron, jest to niewystarczające aby upewnić się, że Google nie wykorzystuje Crawl Budget na niedziałające lub niskiej wartości strony.
Jak zadbać o optymalizację pod kątem Crawl Budget-u?
Pomimo, że właściciele stron internetowych, mogą ustalać wyższe limity crawlingu na swoich kontach Google Search Console, takie ustawienie nie gwarantuje zwiększonego zapotrzebowania na crawling czy też wpływu na to, które strony są analizowane przez Google.
Naturalnym rozwiązaniem wydaje się sprawienie, aby robot Google odwiedzał stronę częściej, ale istnieją jedynie ograniczone metody optymalizacji, które mają bezpośrednie powiązanie ze zwiększonym Crawl Rate.
Wiadomo, że w finansach dobre zarządzanie budżetem nie oznacza zwiększania limitu dostępnych środków. Trzeba tylko rozsądnie planować swoje wydatki. Stosując taką samą zasadę w przypadku Crawl Budget (budżet indeksowania), można zapewnić stronie internetowej lepszy crawling. Poniżej przedstawionych jest kilka strategicznych kroków, jakie należy wykonać, aby pomóc Google wykorzystać Crawl Budget w sposób korzystny dla strony internetowej.

Krok 1: Ustalenie jakie podstrony są odwiedzane przez robota Google
Do niedawna, raport indeksacji w Google Search Console informował właścicieli stron tylko o tym ile próśb o crawling ich strona otrzymywała w ciągu konkretnych dni. Pomimo, że nowy Crawl Stats Report od Google zapewnia bardziej szczegółowe informacje na temat crawlingu, najlepszym sposobem na zrozumienie tego jak Google analizuje stronę jest zapoznanie się z logami serwera.
Gdy Google odwiedza stronę internetową, wykorzystuje ono tzw. user agent. Dzięki temu serwer wie, że dany ruch jest generowany przez robota Google, a nie przez realnego użytkownika.
Właściciele stron analizując treść logów serwerowych uzyskają mnóstwo informacji na temat Crawl Budget dla danej strony. Takie logi ujawniają kilka rzeczy:
- które strony odwiedza User-Agent,
- Ile podstron agent analizuje dziennie,
- informacje o tym czy przeanalizowane strony zawierają różne błędy – w tym 404.
Idealną sytuacją pożądaną przez właścicieli stron jest analizowanie przez Google stron docelowych, które są zoptymalizowane pod kątem słów kluczowych najwyższej wartości. Ponadto właściciele stron nigdy nie powinni marnować budżetu na strony z błędami 404. Google Search Console pokazuje tylko niektóre z błędów 404, ale można zidentyfikować je wszystkie dzięki logom.
Krok 2: Należy przyjąć do wiadomości, że nie wszystkie strony docelowe muszą być pozycjonowane w Google
Głównym powodem, dla którego wiele stron internetowych przedsiębiorstw marnuje swój Crawl Budget jest to, że pozwalają one Google na analizowanie każdej podstrony.
Właściciele stron przedsiębiorstw i e-commerce powinni wiedzieć, które podstrony ich stron są zoptymalizowane pod konwersję. Dodatkowo, warto zorientować się, które podstrony posiadają thin content lub po prostu widzimy w logach serwerowych, oceniając jako niepotrzebny twór. Świetnie jeśli podstrona spełnia cele biznesowe lub buduje warstwę merytoryczną w naszym serwisie, rozwijając topical authority.
Następnie należy wykorzystać każdą możliwość zapewniającą przeznaczenie Crawl Budget przez Google właśnie na takie dobrze działające strony.
Strony docelowe o wysokim potencjale konwersji i pozycjonowania są warte przeznaczania na nie Crawl Budget (budżetu indeksowania). Poniżej znajduje się kilka porad pozwalających upewnić się, że Google uwzględni takie strony w budżecie.
- Zmniejszenie liczby podstron w mapie strony. Należy skupić się wyłącznie na podstronach, które rzeczywiście mają dużą szansę na pozycjonowanie i pozyskiwanie organicznego ruchu.
- Usunięcie źle działających lub niepotrzebnych podstron. Trzeba usunąć te podstrony, które nie wnoszą żadnej wartości w SERP-ie.
Każdemu właścicielowi strony trudno jest odpuścić jakąś treść. Jest jednak o wiele łatwiej zapobiec analizowaniu konkretnych stron przez Google niż zwiększyć ogólny Crawl Budget. Wyczyszczenie strony tak, aby roboty Google miały większe prawdopodobieństwo znalezienia i zaindeksowania najlepszej treści to główny priorytet dla każdego, kto chce rozsądnie wykorzystać swój Crawl Budget.
Krok 3: Wykorzystanie linków wewnętrznych, aby pokazać najlepsze podstrony robotom Google
Po ustaleniu, które podstrony są analizowane przez Google i okrojeniu słabo działających podstron, należy dokonać zmian w mapie strony. Dzięki temu roboty Google będą bardziej skłonne wykorzystywać budżet na właściwe podstrony.
Aby realnie zmaksymalizować taki budżet, strony muszą posiadać wszystko to co jest niezbędne do pozycjonowania. Kluczowe są działania SEO na stronie, ale bardziej zaawansowaną strategią techniczną jest wykorzystanie struktury linkowania wewnętrznego, aby wywindować potencjalnie dobrze działające strony.
W SEO znana jest strategia PageRank sculpting. W przypadku posiadania dużej strony internetowej z tysiącami podstron docelowych, zaawansowany specjalista może przeprowadzić eksperymenty SEO w celu zoptymalizowania profilu linkowania strony wewnętrznej, aby poprawić PageRank.
W przypadku nowej strony internetowej, można osiągnąć korzyść uwzględniając PageRank sculpting w architekturze strony i zwracając uwagę na wartość strony przy każdej tworzonej stronie docelowej.
Poniżej przedstawione są dwie skuteczne strategie analizowania stron w celu określenia, która zapewni najwięcej korzyści w wyniku PageRank sculpting.
- Należy poszukać podstron, które generują dobry ruch, ale posiadają słaby PageRank. Trzeba znaleźć sposoby na to, aby zapewnić takim stronom więcej linków wewnętrznych.
- Należy skupić się na podstronach, które posiadają wiele linków wewnętrznych, ale nie generują dużego ruchu, wyświetleń na liście wyszukiwania oraz są pozycjonowane dla niewielu słów kluczowych. Strony posiadające wiele linków wewnętrznych zwykle posiadają wysoki PageRank. W przypadku braku wykorzystywania PageRank w celu wygenerowania organicznego ruchu na stronie, wówczas jest on marnowany. Lepiej jest przenieść taki PageRank na strony, które radzą sobie lepiej.
Zrozumienie roli odgrywanej przez każdy link na stronie internetowej obejmuje nie tylko wysyłanie robota Google do różnych podstron, ale również uwzględnia dystrybucję wartości linków. Stanowi to ostatni etap optymalizacji Crawl Budget.
Stworzenie prawidłowej struktury linków wewnętrznych może w znaczący sposób poprawić pozycjonowanie podstron generujących dochody.


